En automatisert prosedyre som er skrevet i Microsoft Visual Basic (VB) 6.,0 oppdateringer DAVID ukentlig med følgende prosedyrer: ring en serie av Perl og Java-programmer som laster ned offentlige data gjennom anonymous file transfer protokoller (FTP) (Tabell 1); pakk ut og analysere ønsket merknad data; skape tabulatordelt data filer som er klare for database import, og importere data inn i en Oracle 8 relational database management system (RDBMS) ved hjelp av Oracle ‘ s SQL*Loader-programmet. Microsoft»s IIE web server og Active Server Page teknologi er brukt for å få tilgang til databasen ved hjelp av JavaBeans og structured query language (SQL)., LocusLink tall for Affymetrix probe sett er avledet fra University of Michigan foreninger eller NetAffx . Funksjonelle kommentarer og database kryss-referanser er hentet fra LocusLink, som gir en stabil, human-kuratert representasjoner av gener. For mer detaljert informasjon om datakildene som brukes av DAVID vennligst se FAQ-seksjon på .,
Analyse moduler
DAVID består av fire moduler: Annotation Tool, GoCharts, KeggCharts, og DomainCharts. Annotation Tool er en automatisert metode for funksjonell markering av genet lister. En hvilken som helst kombinasjon av kommentarene data kan velges fra 10 valg ved å velge de riktige rutene (Tabell 2)., Merknadene er lagt til de innsendte genet listen ved å velge last opp-knappen, som gir en HTML-tabell som inneholder brukeren»s opprinnelige listen av identifikatorer som er lagt til med den valgte funksjonelle kommentarer. Unannotated gener er inkludert i utgang med noen innlagte data for sporingsformål.,
GoCharts modul grafisk viser fordelingen av differentially uttrykte gener mellom de funksjonelle kategoriene ved hjelp av kontrollert vokabular av Gene Ontology Consortium (GÅ), som gir en strukturert språk som kan brukes til funksjoner av gener og proteiner i alle organismer selv som kunnskap fortsetter å hope seg opp, og endre ., Språket er strukturert i en directed acyclic graph (DAG), hvor begrepet spesifisitet øker og genom dekning reduseres etter hvert som en beveger seg nedover i hierarkiet. I kontrast med en ekte hierarki, barn vilkårene i en DAG kan ha mer enn én overordnet begrep og kan ha en annen klasse av forholdet med sine ulike foreldre. Strukturen av GO starter med tre hovedkategorier, Biologisk Prosess, Molekylær-Funksjonen, og Cellulære Komponenter., Biologiske Prosessen omfatter et stort biologisk mål, som for eksempel mitose eller metabolisme purine, som er utført av bestilte sammenstillinger av molekylære funksjoner. Molekylær Funksjonen beskriver oppgaver som utføres av de enkelte gen produkter; eksempler er transkripsjonsfaktor og DNA helicase. Mobil Komponent klassifisering typen innebærer subcellular strukturer, steder, og macromolecular komplekser; eksempler på dette er kjernen, telomere, og opprinnelse anerkjennelse komplekse., Etter å ha valgt en type klassifisering, nivåer som bestemmer liste dekning og spesifisitet er valgt ved å velge riktig knapp. Nivå 1 gir høyest liste dekning med minst mengden av begrepet spesifisitet. Med hvert økende nivå dekning synker mens spesifisitet øker slik at nivå 5 gir minst mulig dekning med høyeste sikt spesifisitet.
Klassifisering data vises som et stolpediagram, hvor lengden på linjen representerer antall genet identifikatorer i hver kategori., Brukeren kan angi visualisering parametere for sortering output data og vise kategorier som inneholder minst et minimum antall gener. Hvis du velger et individuelt bar åpner en ny HTML-tabell som viser genet identifikator, LocusLink antall gene navn, nåværende klassifisering, og andre klassifikasjoner for hvert gen i denne kategorien. En «Vis Alle» – knappen, åpnes en ny HTML-tabell som viser alle klassifisering data og en «Vis Kart Data» – knappen åpner en HTML-tabell som inneholder de underliggende kartdata, og dermed tillater brukere å gjenskape tilpasset figur grafikk i et regnearkprogram., Et nytt diagram kan vises for alle utvalg av gener ved å velge klassifisering type og nivå ved hjelp av avkrysningsbokser og radioknapper tilgjengelig innenfor brukeren»s gjeldende side som gjør det mulig for drill-down funksjoner. En opptelling av antall gener forklart er inkludert i produksjonen, og unannotated gener er binned i «uklassifisert» kategori, og dermed gi brukerne med et automatisert system for sporing for gener ikke forklart.
KeggCharts grafisk display fordelingen av differentially uttrykte gener blant KEGG biokjemiske trasé., Hver sti er knyttet til KEGG veien kart, hvor differentially uttrykte gener fra den opprinnelige listen, er uthevet i rødt. I denne visningen gener er videre knyttet til ytterligere kommentarer tilgjengelig gjennom KEGG»s DBGET arkivsystem . Som med GoCharts, kan brukeren angi visualisering parametere for sortering output data og vise kategorier som inneholder minst et minimum antall gener og KeggCharts visualisering arver alle de dynamiske egenskaper av GoCharts.
DomainCharts viser fordelingen av differentially uttrykte gener blant PFAM protein domener ., Hvert domene betegnelsen er knyttet til Et Domene Database (CDD) av National Center for Bioteknologi Information (NCBI), der informasjon om domenet funksjon, struktur og rekkefølge er lett tilgjengelig. Som med GoCharts og KeggCharts, kan brukeren angi visualisering parametere for sortering output data og vise kategorier som inneholder minst et minimum antall gener og DomainCharts visualisering arver alle de dynamiske egenskaper av GoCharts og KeggCharts. For ytterligere informasjon om funksjonalitet av DAVID besøke FAQ-seksjon på .,
ved Hjelp av DAVID meg funksjonelle kommentar
for Å demonstrere funksjonalitet av DAVID vi analysert en liste av gener differentially til uttrykk i menneskelig perifert blod mononukleære celler (PBMCs) etter inkubering med HIV-1 konvolutt proteiner. Detaljer av den eksperimentelle, RNA forberedelse, og GeneChip hybridisering prosedyrer, sammen med detaljer av chip-til-chip normalizations og statistisk analyse av differensiert genuttrykk er gitt i cicala har et al. ., Kort primære menneskelige PBMCs og monocytt-avledet makrofager ble inkubert i 16 timer med HIV-1 konvolutt protein (gp120). Høy tetthet oligonukleotid microarrays (Affymetrix HU-95EN GeneChip) ble brukt til å overvåke gp120-indusert transcriptional hendelser. Denne analysen resulterte i identifisering av 402 differentially uttrykte gener.
Mens 16 gener modulert av HIV-1 gp120 har tidligere vært forbundet med HIV-replikasjon og/eller konvolutt signalering, de resterende gener som er av ukjent funksjon eller en som aldri har vært forbundet med HIV-1 eller gp120., Konvertere denne listen av gener i biologisk betydning krever innhenting av relevant informasjon fra ulike dataregistre. For mange forskere er denne prosessen består av iterativ å bla gjennom flere databaser for hvert gen, manuelt gathering gen-spesifikk informasjon om sekvens, funksjon, vei, og sykdom association. I kontrast, systematisk tilnærming av DAVID samtidig legger biologisk rik informasjon avledet fra flere offentlige datakilder til lister av gener i parallell., Valg av DAVID»s merknadsverktøy og laste opp liste over 402 differentially uttrykte gener starter funksjonelle kommentar og analyse av hele datasettet. Når de er sendt, genet listen er lagret for hele analysen økt, som tillater brukere å bytte mellom moduler uten å måtte sende inn data.
merknadsverktøy
Annotation Tool gir flere merknad valg og bygger en tabellvisning av brukere gen i listen over tilgjengelige kommentarer (Tabell 2)., Du velger kommentar-feltene Genet Symbol, LocusLink, OMIM, Unigene, Referanse Rekkefølge, og Genet Navn som følges ved å velge «last opp» knappen lager en HTML-tabell i nettleseren som inneholder alle genene og deres tilgjengelig kommentarer, hvor genet identifikatorer, beskrivende og klassifisering data hentes fra databasen og lagt til genet listen (Figur 1). Genet identifikatorer, for eksempel Genet Symbol og LocusLink er hyperkoblet til ekstra gen-spesifikke data tilgjengelig på sine opprinnelige kilder, og dermed gir i dybden gen-spesifikke detaljer og kommenteres stamtavler., Klassifisering data og funksjonelle sammendrag kan brukes til raskt å søke etter informasjon som er relevant for forskeren»s eksperimentelle systemet. Serveren tid nødvendig for gjennomføring av denne modulen korrelerer lineært med størrelsen av genet listen, og tar mindre enn 45 sekunder for lister på opp til 1000 gener (Figur 2, tall i parentes representerer r2-verdier). Disse resultatene viser kraften og effektiviteten av en integrert tilnærming til de funksjonelle markering av store datasett.,

Utgang av Annotation Tool. Vist er lagt markeringer for det første flere Affymetrix probe sett i en HTML-tabell som inneholder alle 402 oppføringer. Kategoriske informasjon om eksperimentelle forhold, ble levert sammen med Affymetrix probe-sett identifikatorer og inkludert i resultatet i verdi-kolonnen. Identifikatorer, for eksempel Symbol, LocusLink, OMIM, RefSeq, og Unigene accessions er hyper-knyttet til deres opprinnelse kilder for mer utfyllende informasjon., Tekst inkludert i sammendraget felt er avledet fra beskrivende, funksjonell informasjon gitt i NCBI»s LocusLink rapporter.
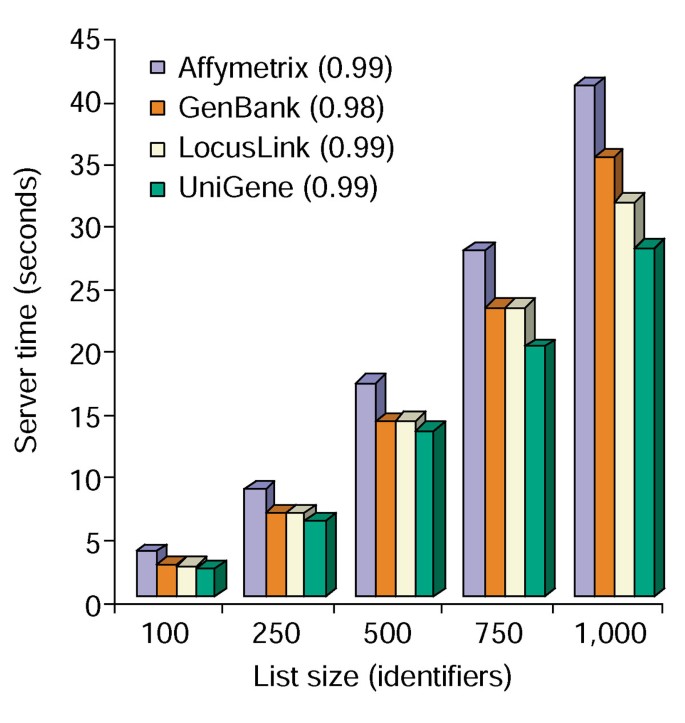
Tid analyse av Annotation Tool. Server tiden som kreves (y-aksen) for samtidig å legge alle 10 kommentar alternativer til genet lister som varierer i størrelse fra 100 til 1000 (x-aksen)., Gjennomsnittet av tre forsøk for genet lister som inneholder Affymetrix, GenBank, LocusLink, og UniGene identifikatorer er vist, og tallene i parentes representerer r2 verdi av sammenhengen mellom gen-listen størrelse og server den tiden som kreves for kommentar.
GoCharts
Velge den GoCharts modul åpnes et nytt vindu med en rekke valg., Brukerne kan velge mellom tre hovedtyper av klassifisering (biologisk prosess, molekylær-funksjonen, og mobil komponent) og fem nivåer på en merknad som representerer begrepet dekning og spesifisitet (se Analyse § Moduler). En hvilken som helst kombinasjon av standard og dekningsgrad nivå kan være angitt. Det finnes også alternativer for å kommentere genet lister med alle GÅ vilkårene tilgjengelig, eller bare de mest konkrete vilkår som er referert til som terminal noder., Muligheten til å velge forskjellige nivåer av begrepet spesifisitet gir nødvendig fleksibilitet og dermed tillater forskere å finne ut dynamisk hvilket nivå av dekning og spesifisitet passer best til deres data og fasen av analysen. For eksempel, et tidlig stadium analyser kan bestå i å legge tilmerknader genet lister med svært generelle vilkårene for å få en bred forståelse av data. I dette tilfellet, å velge biologiske prosessen og nivå 1 klassifiserer gener ved bruk av generelle begreper som «død» og «celle kommunikasjon»., Ved hjelp av økt sikt spesifisitet muliggjør utvinning av mer detaljert funksjonell informasjon. I dette tilfellet velger biologiske prosessen og nivå 5 klassifiserer gener ved hjelp av begreper som «apoptotic mitokondrie endringer» og «chemosensory oppfatning».
Imidlertid økt sikt spesifisitet kommer en kostnad, i det som det øker liste dekning reduseres (Figur 3). I våre studier finner vi at nivå 2 vanligvis opprettholder god dekning, mens det også gir meningsfullt begrep spesifisitet., Figur 4a viser hvordan GoCharts visualisering raskt avslører at 35 differentially uttrykte gener som er involvert i «stress responses». Hvert GÅ begrepet kan ses i treet eller DAG visninger ved hyperkoblinger til QuickGO .
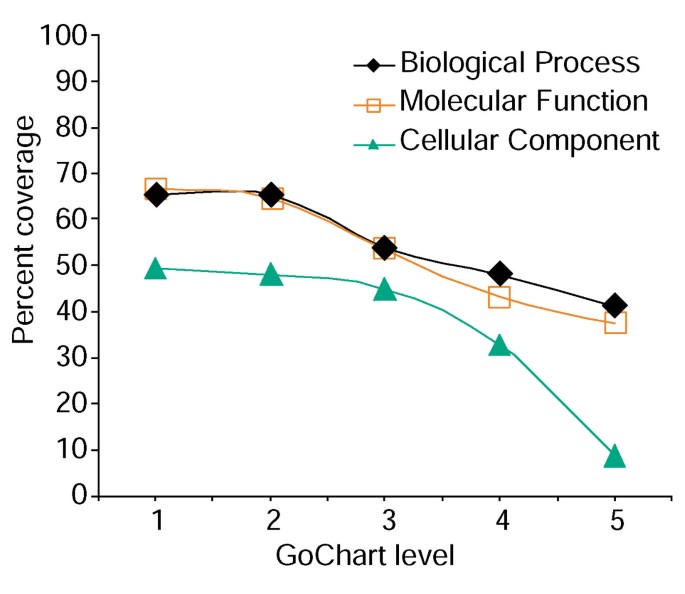
Analyse av gen-listen dekning ved hjelp av GoCharts. En liste over 402 Affymetrix probe sett identifikatorer ble forklart med Proteome tildelt funksjonelle standarder gitt av LocusLink., Prosent dekning representerer antall gener ut av 402 som ble forklart på en term-spesifisitet nivå innen Biologisk Prosess, Molekylær-Funksjonen, og Mobil Komponent klassifisering typer. Prosent dekning reduseres etter hvert som begrepet spesifisitet øker.
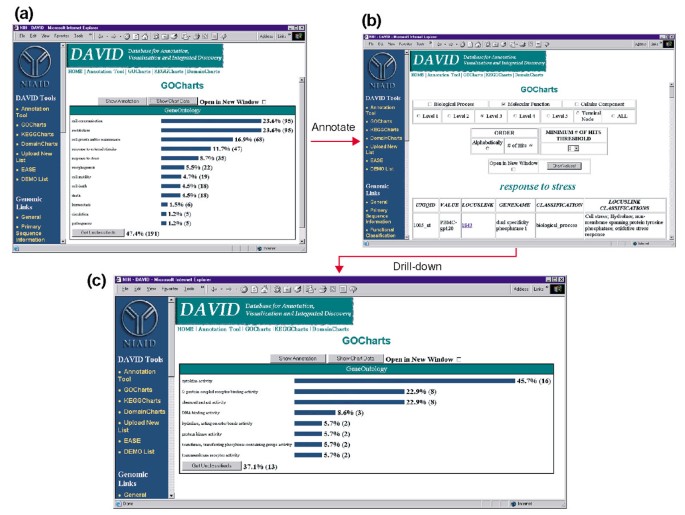
Utgang av GoCharts. (a) En bar diagram som viser fordelingen av differentially uttrykte gener blant Gene Ontology (GÅ) Biologiske Prosesser., Parametre ble satt til å GÅ på nivå 2, en hit terskelen til fem, og produksjonen var sortert etter traff teller. Blå linjene er knyttet til ytterligere kommentar data som er vist i (b). Å velge den blå linjen i (a) svarer til «svar på stress» åpner en HTML-tabell som viser LocusLink gene navn, nåværende klassifisering, og andre klassifisering data for gener i denne kategorien. (c) Dette er en undergruppe av gener som er involvert i «stressrespons» ble videre karakterisert ved å velge GÅ Molekylær-Funksjonen, GÅR du på nivå 3, en hit terskel for 2, og sorteres ved å treffe teller., Å velge «Chart Verdier» knappen lager en ny histogram avsløre at 16 av 35 stress-respons-gener koder for proteiner med cytokin aktivitet.,
Fordi HIV-1 har en stor innvirkning på funksjonen av celler i immunsystemet, og deres evne til å gjennomføre stress reaksjoner, vi valgte histogrammet bar som representerer antallet gener som er involvert i stressrespons, som åpner en HTML-tabell som inneholder Affymetrix identifikator, LocusLink antall gene navn, nåværende klassifisering, og andre klassifikasjoner for alle 35 gener (Figur 4b)., Nå som vi har redusert våre genet listen til de gener som er involvert i stressrespons, vi videre preget dette delsettet ved å gjenta GoCharts prosedyre tilgjengelig på toppen av stress-respons HTML-tabellen. Ved å velge molekylær funksjon, nivå 3 produserer en ny histogram som raskt avslører at nesten halvparten (16/35) av stress-respons-gener har cytokin aktivitet (Figur 4c)., Faktisk, cytokiner har vist seg å spille en viktig rolle i HIV-1 livssyklus og resultatene her tyder på at behandling av PBMCs med HIV-1 konvolutt proteiner betydelig modulerer transkripsjon av mange cytokin gener. Den effektivitet som GoCharts systematisk oppsummert dette i stor dataset med grafiske effekter, mens resten er knyttet til primær data og eksterne ressurser, drastisk forbedret discovery prosessen.,
KeggCharts
Figur 5a viser resultatet av KeggCharts med et histogram som viser fordelingen av differentially uttrykte gener blant biokjemiske trasé. Figuren viser at en KEGG veien til apoptosis omfatter fem gener som er forårsaket av HIV-1 gp120. Å velge den veien navnet åpner den tilsvarende KEGG biokjemiske veien kart og høydepunkter i rødt omriss på differentially uttrykte gener fungerer i at veien (Figur 5b). I denne visningen gener er videre knyttet til ytterligere kommentarer tilgjengelig gjennom KEGG»s DBGET arkivsystem ., Merk at bare fire gener i KEGG apoptosis veien er uthevet i rødt, mens den KeggCharts verktøyet kartlagt fem Affymetrix probe stiller til apoptosis veien. Denne forskjellen er på grunn av det faktum at to av Affymetrix probesets er rettet mot det samme «TNF-alfa» genet.
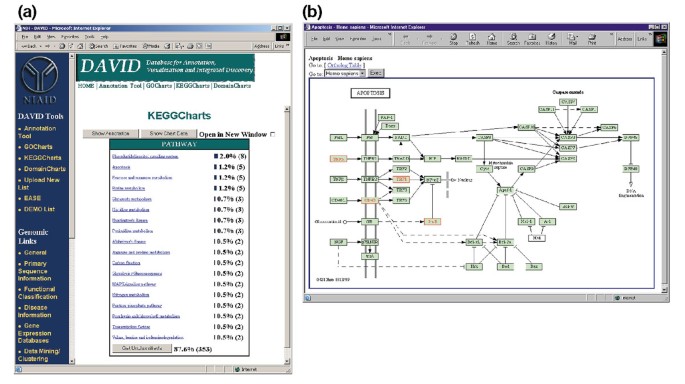
Utgang av KeggCharts. (en) Visualisering diagram som viser fordelingen av 402 gener blant KEGG biokjemiske trasé. Hit grensen ble satt til tre og resultatet ble sortert ved traff teller., Det store antallet av gradert identifikatorer er på grunn av det faktum at KEGG er biokjemiske-veien sentriske og dermed gir lav dekning av genet lister. På samme måte som ved utgangen av GoCharts, blå linjene representerer antall gener i hver vei. Å velge en blå bar åpner en HTML-tabell som viser LocusLink gene navn, nåværende klassifisering, og andre klassifisering data for gener i at veien (data ikke vist)., (b) KEGG biokjemiske vei som vises følgende valg av vei navnet «apoptosis» i (a) skildrer fire differentially uttrykte gener innenfor apoptosis vei ved å merke dem i lys grønn og rød. Det faktum at KEGG vei høydepunkter bare fire gener mens KeggChart kart fem Affymetrix probe stiller til apoptosis vei er på grunn av det faktum at to probe setter target samme «TNF-alfa» genet.,
DomainCharts
DomainCharts er operativt beslektet med både KeggCharts og GoCharts, bortsett fra at resultatene visuelt viser fordelingen av gener blant PFAM protein domener (Figur 6a). Den DomainCharts histogram identifiserer 16 gener med kinase domener (pkinase), sannsynligvis som reflekterer effekten av HIV-1 gp120 på signal transduksjon maskiner. Diagrammet også identifiserer seks gener med interleukin-8-domener (IL-8), et domene som representerer en svært bevart motiv blant stress-respons cytokiner., Velge domene navnet «IL8» åpner Bevart Domene Database (CDD) side tilsvarende det som PFAM domene (Figur 6b). Denne siden gir detaljert sekvens, struktur og funksjonelle informasjon om IL-8 domene og proteiner som inneholder det.
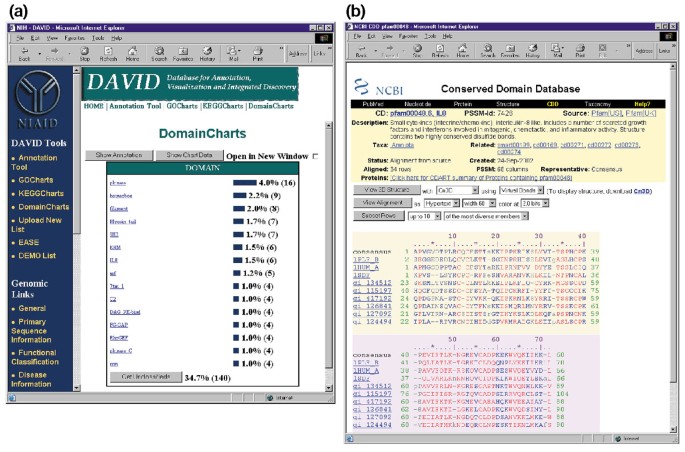
Utgang av DomainCharts. (en) Visualisering diagram som viser fordelingen av 402 gener blant protein domener. Parametrene ble satt til et minimum hit terskelen til fire og utgang var sortert etter traff teller., Lignende til utgangen av GoCharts og KeggCharts, blå linjene representerer antall gener som inneholder det aktuelle domenet. Å velge en blå bar åpner en HTML-tabell som viser LocusLink gene navn, nåværende klassifisering, og andre klassifisering data for gener i at veien (data ikke vist)., (b) Velge domene navnet «IL8» i (a), som inneholder seks differentially uttrykte gener, bringer brukeren til en ny side som inneholder utgang fra Bevart Domene Database (CDD) av NCBI, som gir detaljert informasjon om IL-8-domenet, herunder strukturelle informasjon, flere sekvens justeringer, og beskrivende informasjon om domenet og proteiner som er i besittelse av det.