een geautomatiseerde procedure geschreven in Microsoft Visual Basic (VB) 6.,0 werkt DAVID weekly bij met de volgende procedures: bel een reeks Perl-en Java-toepassingen die openbare gegevens downloaden via anonieme bestandsoverdrachtsprotocollen (FTP) (Tabel 1); pak de gewenste annotatiegegevens uit en ontleden; maak tab-gescheiden gegevensbestanden klaar voor database-import; en importeer gegevens in een Oracle 8i relational database management system (RDBMS) met behulp van Oracle ‘ s SQL*Loader applicatie. Microsoft ‘ s IIe web server en Active Server pagina technologie worden gebruikt om toegang te krijgen tot de database met behulp van JavaBeans en de structured query language (SQL)., LocusLink nummers voor Affymetrix sonde sets zijn afgeleid van University of Michigan associations of NetAffx . De functionele annotaties en de verwijzingen van het gegevensbestand worden afgeleid van LocusLink, die stabiele, mens-curated representaties van genen verstrekt. Voor meer gedetailleerde informatie over de gegevensbronnen die door DAVID worden gebruikt, zie de FAQ sectie op .,
Analysemodules
DAVID bestaat uit vier hoofdmodules: Annotatietool, GoCharts, KeggCharts en DomainCharts. Het Annotatiehulpmiddel is een geautomatiseerde methode voor de functionele annotatie van genlijsten. Elke combinatie van annotatiegegevens kan worden gekozen uit 10 opties door het selecteren van de juiste selectievakjes (Tabel 2)., De annotaties worden toegevoegd aan de ingediende genlijst door de uploadknop te selecteren, die een HTML-lijst retourneert die de originele lijst van identifiers van de gebruiker bevat die met de gekozen functionele annotaties worden toegevoegd. Niet-geannoteerde genen zijn opgenomen in de output zonder toegevoegde gegevens voor het volgen van doeleinden.,
De GoCharts module grafische weergave van de verdeling van deze uitgedrukt genen onder functionele categorieën met behulp van de gecontroleerde woordenschat van de Gene Ontology Consortium (GO), die zorgt voor een gestructureerde taal die kan worden toegepast om de functies van genen en eiwitten in alle organismen, zelfs als de kennis blijft zich ophopen en wijzigen ., De taal is gestructureerd in een gerichte acyclische grafiek (DAG), waarin de term specificiteit toeneemt en de genoomdekking afneemt als men zich onderaan de hiërarchie beweegt. In tegenstelling tot een echte hiërarchie kunnen kindtermen in een DAG meer dan één ouderterm hebben en een andere klasse van relatie met de verschillende ouders hebben. De structuur van GO begint met drie hoofdcategorieën, biologisch proces, moleculaire functie en cellulaire Component., Het biologische proces omvat brede biologische doelstellingen, zoals Mitose of purinemetabolisme, die door geordende samenstellingen van moleculaire functies worden bereikt. De moleculaire functie beschrijft de taken die door individuele genproducten worden uitgevoerd; voorbeelden zijn transcriptiefactor en helicase van DNA. Het cellulaire Componentclassificatietype impliceert subcellular structuren, plaatsen, en macromoleculaire complexen; de voorbeelden omvatten complexe kern, telomeer, en oorsprongherkenning., Na het kiezen van een classificatietype worden niveaus die de dekking en specificiteit van de lijst bepalen, gekozen door de juiste keuzerondje te selecteren. Niveau 1 biedt de hoogste lijst dekking met de minste hoeveelheid term specificiteit. Bij elk stijgend niveau neemt de dekking af terwijl de specificiteit toeneemt, zodat niveau 5 de minste hoeveelheid dekking biedt met de hoogste termspecificiteit.
classificatiegegevens worden weergegeven als een staafdiagram, waarbij de lengte van de staaf het aantal genidentifiers in elke categorie vertegenwoordigt., De gebruiker kan visualisatieparameters instellen voor het sorteren van outputgegevens en het weergeven van categorieën die ten minste een minimum aantal genen bevatten. Het selecteren van een individuele bar opent een nieuwe HTML-lijst die de genidentificatie, Locuslinkaantal, gennaam, de huidige classificatie, en andere classificaties voor elk gen in die categorie weergeven. Een knop ” Toon alles “opent een nieuwe HTML-tabel met alle classificatiegegevens en een knop” Toon Grafiekgegevens ” opent een HTML-tabel met de onderliggende grafiekgegevens, waardoor gebruikers aangepaste grafiekafbeeldingen in een spreadsheetprogramma opnieuw kunnen maken., Een nieuwe grafiek kan worden weergegeven voor elke subset van genen door het selecteren van de classificatie type en niveau met behulp van de selectievakjes en keuzerondjes beschikbaar in de huidige pagina van de gebruiker die het mogelijk maken voor drill-down mogelijkheden. Een telling van het aantal geannoteerde genen is inbegrepen in de output, en de niet-geannoteerde genen worden gebinned in de “niet-geclassificeerde” categorie, waarbij gebruikers van een geautomatiseerd volgsysteem voor niet geannoteerde genen worden voorzien.
KeggCharts geven grafisch de verdeling weer van differentieel tot expressie gebrachte genen over biochemische Kegg-routes., Elke weg wordt verbonden met de kaart van de weg van KEGG, waarin differentieel uitgedrukte genen van de originele lijst in rood worden gemarkeerd. In deze mening worden de genen verder verbonden aan extra annotaties beschikbaar door KEGG”s dbget retrievalsysteem . Net als bij GoCharts kan de gebruiker visualisatieparameters instellen voor het sorteren van outputgegevens en het weergeven van categorieën die ten minste een minimum aantal genen bevatten en de visualisatie van KeggCharts erft alle dynamische kenmerken van GoCharts.
DomainCharts tonen de verdeling van differentieel tot expressie gebrachte genen over PFAM-eiwitdomeinen ., Elke domeinaanduiding is gekoppeld aan de geconserveerde domeindatabase (CDD) van het National Center for Biotechnology Information (NCBI), waar details over domeinfunctie, – structuur en-volgorde direct beschikbaar zijn. Net als bij GoCharts en KeggCharts, kan de gebruiker visualisatieparameters instellen voor het sorteren van outputgegevens en het weergeven van categorieën die ten minste een minimum aantal genen bevatten en de domaincharts visualisatie erft alle dynamische kenmerken van GoCharts en KeggCharts. Voor meer informatie over de functionaliteit van DAVID bezoek de FAQ sectie op .,
met behulp van DAVID om functionele annotatie te mineren
om de functionaliteit van DAVID aan te tonen analyseerden we een lijst van genen die differentieel tot expressie komen in menselijke mononucleaire cellen uit perifeer bloed (PBMC ‘ s) na incubatie met HIV-1-envelop-eiwitten. De Details van de experimentele, de voorbereiding van RNA, en genechiphybridisatieprocedures, samen met details van de Spaander-aan-spaandernormalisaties en statistische analyse van differentiële genuitdrukking worden verstrekt in Cicala et al. ., Kort, primaire menselijke PBMC ‘ s en monocyt-afgeleide macrofagen werden gedurende 16 uur geïncubeerd met HIV-1 envelop eiwit (gp120). Microarrays met hoge dichtheid oligonucleotide (Affymetrix HU-95A GeneChip) werden gebruikt om gp120-geïnduceerde transcriptionele gebeurtenissen te controleren. Deze analyse resulteerde in de identificatie van 402 differentieel tot expressie gebrachte genen.
terwijl 16 genen gemoduleerd door HIV-1 gp120 eerder in verband werden gebracht met HIV-replicatie en/of envelope-signalering, zijn de resterende genen van onbekende functie of zijn ze nooit in verband gebracht met HIV-1 of gp120., Het omzetten van deze lijst van genen in biologische betekenis vereist het verzamelen van relevante informatie van verscheidene gegevensopslagplaatsen. Voor vele onderzoekers bestaat dit proces uit het iteratieve doorbladeren door verscheidene databases voor elk gen, handmatig het verzamelen van Gen-specifieke informatie betreffende opeenvolging, functie, weg, en ziekteassociatie. In tegenstelling, voegt de systematische benadering van DAVID tegelijkertijd biologisch rijke informatie uit verscheidene openbare gegevensbronnen aan lijsten van genen parallel wordt afgeleid., Het selecteren van het Annotatiehulpmiddel van DAVID en het uploaden van de lijst van 402 differentieel uitgedrukte genen initieert de functionele annotatie en analyse van de volledige dataset. Zodra ingediend, wordt de genlijst opgeslagen voor de volledige analysesessie, toestaand gebruikers om tussen modules te schakelen zonder gegevens opnieuw te moeten verzenden.
Annotatietool
Het Annotatietool biedt verschillende annotatieopties en bouwt een tabelweergave op van de gebruikersgenlijst en de beschikbare annotaties (Tabel 2)., Het kiezen van het gensymbool van annotatievelden, LocusLink, Omim, Unigene, Referentieopeenvolging, en Gennaam gevolgd door de knop “Uploaden” te selecteren produceert een HTML-lijst in de webbrowser die alle genen en hun beschikbare annotaties bevat, waar de genidentificators, beschrijvende en classificatiegegevens uit het gegevensbestand worden getrokken en aan de genlijst worden toegevoegd (figuur 1). De identificatiemiddelen van het gen zoals Gensymbool en LocusLink zijn hyperlinked aan extra gen-specifieke gegevens beschikbaar bij hun originele bronnen, zo verstrekkend diepgaande gen-specifieke details en annotatiestambomen., Classificatiegegevens en functionele samenvattingen kunnen worden gebruikt om snel te scannen op informatie die relevant is voor het experimentele systeem van de onderzoeker. De servertijd die nodig is voor de uitvoering van deze module correleert lineair met de grootte van de genenlijst en duurt minder dan 45 seconden voor lijsten van maximaal 1.000 genen (Figuur 2, getallen tussen haakjes vertegenwoordigen r2 waarden). Deze resultaten tonen de kracht en efficiëntie van een geïntegreerde benadering van de functionele annotatie van grote datasets.,

output of Annotation Tool. Weergegeven worden annotaties toegevoegd voor de eerste Affymetrix probe sets in een HTML tabel die alle 402 items bevat. Categorische informatie over de experimentele condities werd ingediend samen met de Affymetrix probe-set identifiers en opgenomen in de output in de waarde kolom. Identifiers zoals Symbol, LocusLink, omim, RefSeq, en Unigene toetredingen zijn hyper-gekoppeld aan hun oorsprong bronnen voor meer gedetailleerde informatie., De tekst in de samenvattingsvelden is afgeleid van beschrijvende, functionele informatie uit de LocusLink-rapporten van NCBI.
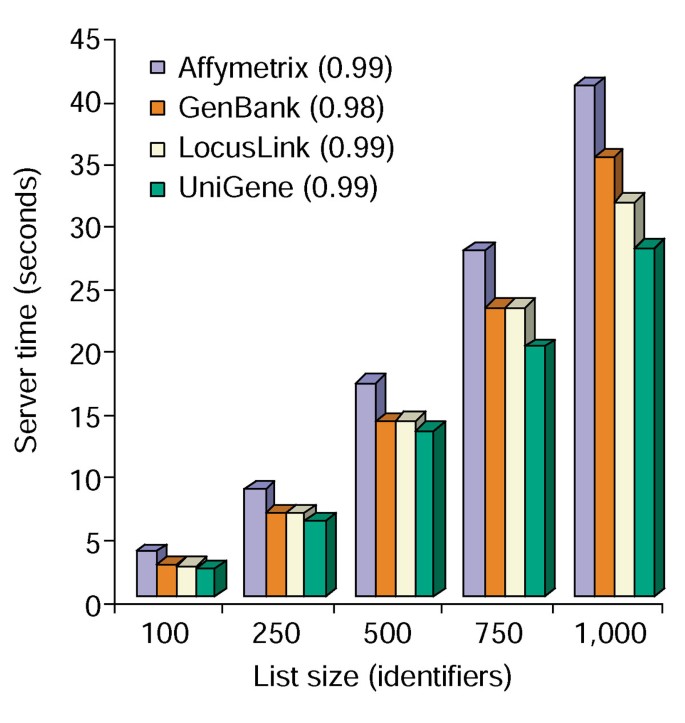
tijdanalyse van Annotatietool. Vereiste servertijd (y-as) om gelijktijdig alle 10 annotatieopties aan genlijsten toe te voegen die zich in grootte van 100 tot 1.000 (x-as) uitstrekken., Het gemiddelde van drie proeven voor genlijsten die Affymetrix, GenBank, LocusLink, en UniGene identifiers bevatten wordt getoond en de aantallen tussen haakjes vertegenwoordigen r2 waarde van de correlatie tussen gen-lijst grootte en de servertijd die voor annotatie wordt vereist.
GoCharts
het kiezen van de gocharts module opent een nieuw venster met een verscheidenheid opties., De gebruikers kiezen tussen drie algemene types van classificatie (biologisch proces, moleculaire functie, en cellulaire component) en vijf niveaus van annotatie die termdekking en specificiteit vertegenwoordigen (Zie sectie Analysemodules). Elke combinatie van classificatie en dekkingsniveau kan worden gespecificeerd. Ook inbegrepen zijn opties om genlijsten met alle beschikbare termen te annoteren gaan of slechts de meest specifieke termen, die als eindknooppunten worden bedoeld., De optie om verschillende niveaus van termspecificiteit te kiezen biedt de nodige flexibiliteit en stelt onderzoekers dus in staat om dynamisch te bepalen welk niveau van dekking en specificiteit het beste past bij hun gegevens en analysestadium. Bijvoorbeeld, kunnen vroege-stadiumanalyses bestaan uit het annoteren van genlijsten met zeer algemene termen om een breed begrip van de gegevens te krijgen. In dit geval, selecteert het selecteren van biologisch proces en niveau 1 genen gebruikend algemene termen zoals “dood” en “celcommunicatie”., Het gebruik van verhoogde term specificiteit vergemakkelijkt de extractie van meer gedetailleerde functionele informatie. In dit geval selecteert het selecteren van biologisch proces en niveau 5 genen met behulp van termen zoals “apoptotische mitochondriale veranderingen” en “chemosensorische perceptie”.
echter, verhoogde term specificiteit komt een kosten, in die zin dat als het verhoogt lijst dekking afneemt (Figuur 3). In onze studies vinden we dat niveau 2 doorgaans een goede dekking behoudt en tegelijkertijd betekenisvolle termspecificiteit biedt., Figuur 4a illustreert hoe de gocharts visualisatie snel onthult dat 35 differentieel tot expressie gebrachte genen betrokken zijn bij”stressreacties”. Elke Go term kan worden bekeken in de boom of dag weergaven door hyperlinks naar QuickGO .
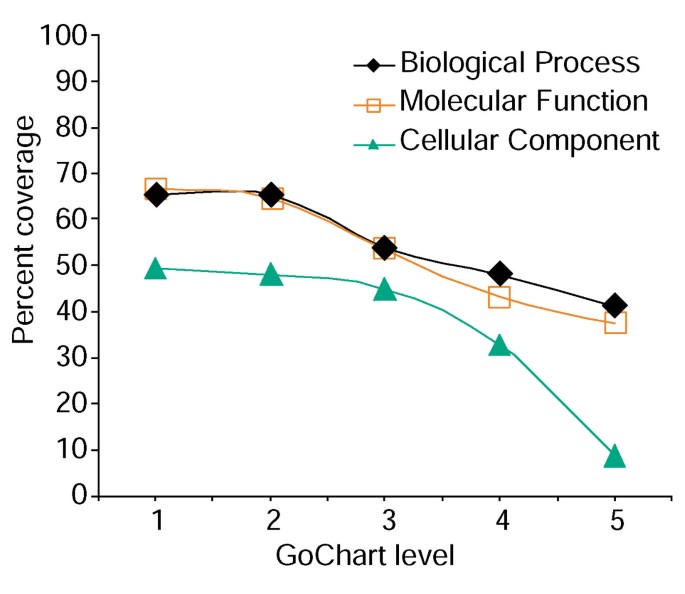
analyse van de dekking van de genenlijst met behulp van GoCharts. Een lijst van 402 Affymetrix sonde set identifiers werden geannoteerd met de Proteome toegewezen functionele classificaties verstrekt door LocusLink., De percentagedekking vertegenwoordigt het aantal genen uit 402 die op een term-specificiteitsniveau binnen het biologische proces, moleculaire functie, en cellulaire Componentclassificatietypes werden geannoteerd. Procent dekking neemt af als term specificiteit toeneemt.
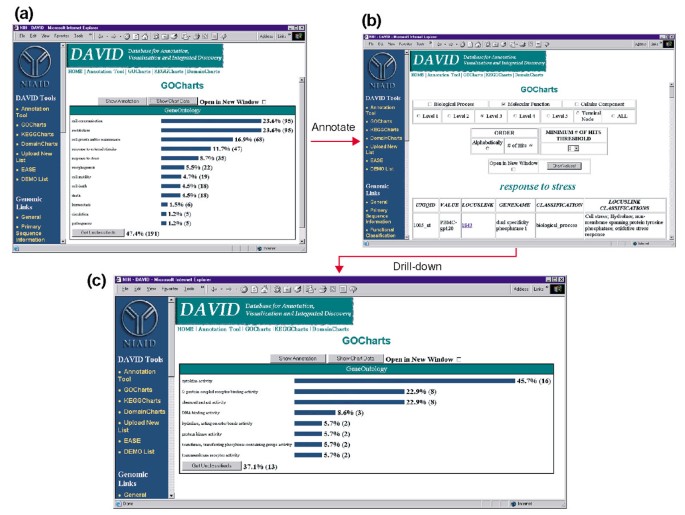
output van GoCharts. (a) een staafdiagram met de verdeling van differentieel tot expressie gebrachte genen over biologische processen in Genontologie (GO)., Parameters werden ingesteld om niveau 2 te gaan, een hit drempel van vijf, en de output werd gesorteerd op hit count. Blauwe balken zijn gekoppeld aan aanvullende annotatiegegevens weergegeven onder (b). Het selecteren van de blauwe balk in (a) die overeenkomt met “respons op stress” opent een HTML-tabel met de LocusLink, gennaam, huidige classificatie en andere classificatiegegevens voor de genen in die categorie. (c) deze subgroep van genen die betrokken zijn bij “stressrespons” werd verder gekenmerkt door het selecteren van Go moleculaire functie, GO niveau 3, een hit drempel van 2, en gesorteerd op HIT telling., Het selecteren van de” grafiek waarden ” knop creëert een nieuw histogram waaruit blijkt dat 16 van de 35 stress-respons genen coderen eiwitten bezitten cytokine activiteit.,
omdat HIV-1 een grote invloed heeft op de functie van cellen van het immuunsysteem en hun vermogen om stressreacties uit te voeren, hebben we de histogrambalk geselecteerd die het aantal genen vertegenwoordigt dat betrokken is bij stressrespons, waardoor een HTML-tabel wordt geopend met de Affymetrix-identifier, het LocusLink-nummer, de gennaam, de huidige classificatie en andere classificaties voor alle 35 genen (figuur 4b)., Nu we onze genenlijst hebben gereduceerd tot die genen die betrokken zijn bij stressreacties, hebben we deze subset verder gekarakteriseerd door de GoCharts procedure te herhalen die beschikbaar is aan de bovenkant van de stress-respons HTML tabel. Het kiezen van moleculaire functie, niveau 3 produceert een nieuw histogram dat snel onthult dat bijna de helft (16/35) van de stress-respons genen bezitten cytokine activiteit (figuur 4c)., Cytokines spelen inderdaad een belangrijke rol in de HIV-1 levenscyclus en de hier verkregen resultaten suggereren dat de behandeling van PBMC ‘ s met hiv-1 envelopproteã nen de transcriptie van talrijke cytokinegenen significant moduleert. De efficiëntie waarmee GoCharts deze grote dataset systematisch samenvatte met grafische weergaven, terwijl hij gekoppeld bleef aan primaire gegevens en externe bronnen, verbeterde het ontdekkingsproces drastisch.,
KeggCharts
figuur 5a toont de output van KeggCharts met een histogram dat de verdeling van differentieel tot expressie gebrachte genen over biochemische routes weergeeft. De grafiek toont aan dat een Kegg-weg van apoptosis vijf genen omvat die door HIV-1 gp120 worden veroorzaakt. Het selecteren van de pathway naam opent de overeenkomstige Kegg biochemische pathway map en hoogtepunten in rode schets de differentieel uitgedrukte genen functioneren in die pathway (figuur 5b). In deze mening worden de genen verder verbonden aan extra annotaties beschikbaar door KEGG”s dbget retrievalsysteem ., Merk op dat slechts vier genen in de weg van KEGG apoptosis in rood worden gemarkeerd, terwijl het Hulpmiddel van KeggCharts vijf reeksen van de Affymetrix sonde aan de weg van apoptosis in kaart bracht. Dit verschil is toe te schrijven aan het feit dat twee van de Affymetrix-sondesets hetzelfde “TNF-alpha” gen richten.
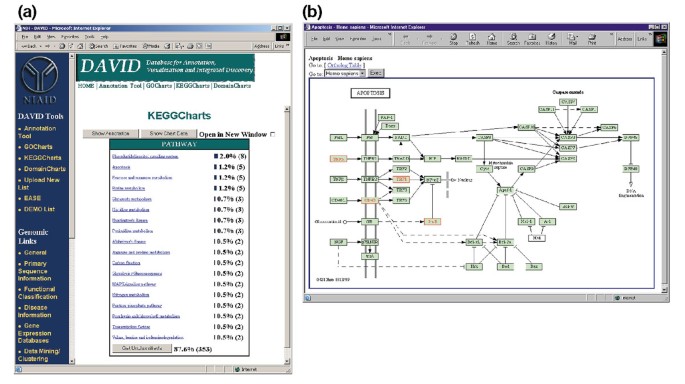
output van KeggCharts. (a) Visualisatiegrafiek die de verdeling van 402 genen tussen Kegg biochemische wegen toont. De hit drempel werd ingesteld op drie en de output werd gesorteerd op hit count., Het grote aantal niet geclassificeerde identificatoren is toe te schrijven aan het feit dat KEGG biochemisch-weg centric is en zo lage dekking van genlijsten verstrekt. Op dezelfde manier als de output van GoCharts, vertegenwoordigen de blauwe balken het aantal genen in elke weg. Het selecteren van een blauwe balk opent een HTML-tabel die de LocusLink, gennaam, huidige classificatie, en andere classificatiegegevens voor de genen in die weg toont (gegevens niet getoond)., (b) de Kegg biochemische route die verschijnt na de selectie van de pathway naam “apoptosis” in (a) toont vier differentieel tot expressie gebrachte genen binnen de apoptosis route door ze te markeren in licht groen en rood. Het feit dat de Kegg-weg slechts vier genen benadrukt terwijl de KeggChart vijf Affymetrix-sets aan de apoptosisweg in kaart brengt is toe te schrijven aan het feit dat twee sets van de sonde hetzelfde “TNF-alpha” gen richten.,
DomainCharts
domaincharts zijn operationeel verwant aan zowel KeggCharts als GoCharts, behalve dat de resultaten visueel de verdeling van genen over PFAM-eiwitdomeinen weergeven (figuur 6a). Het histogram domaincharts identificeert 16 genen met kinase domeinen( pkinase), waarschijnlijk als gevolg van de effecten van HIV-1 gp120 op de signaaltransductie machines. De grafiek identificeert ook zes genen met interleukin-8 domeinen (IL-8), een domein dat een hoogst behouden motief onder spanning-reactie cytokines vertegenwoordigt., Als u de domeinnaam “IL8” selecteert, wordt de behouden domeindatabase (CDD) – pagina geopend die overeenkomt met dat PFAM-domein (figuur 6b). Deze pagina geeft gedetailleerde sequentie, structuur en functionele informatie over het IL-8 domein en de eiwitten die het bevatten.
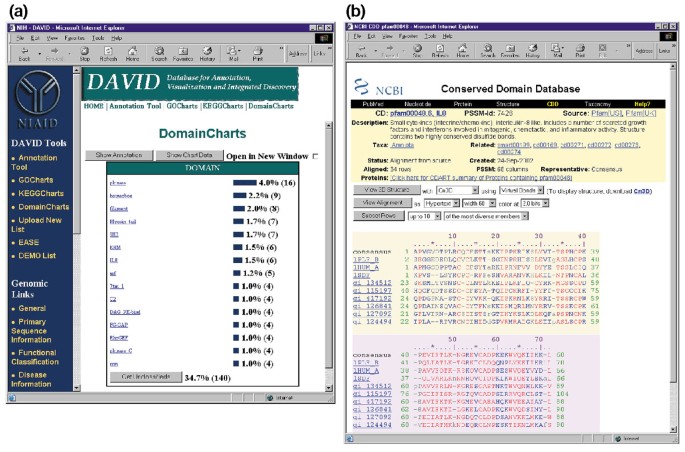
output van DomainCharts. (a) visualisatiegrafiek die de verdeling van 402 genen tussen eiwitdomeinen toont. De parameters werden ingesteld op een minimale hit drempel van vier en de output werd gesorteerd op hit count., Gelijkaardig aan de output van GoCharts en KeggCharts, vertegenwoordigen de blauwe balken het aantal genen die dat specifieke domein bevatten. Het selecteren van een blauwe balk opent een HTML-tabel die de LocusLink, gennaam, huidige classificatie, en andere classificatiegegevens voor de genen in die weg toont (gegevens niet getoond)., (b) het selecteren van de domeinnaam “IL8” in (a), die zes differentieel tot expressie gebrachte genen bevat, brengt de gebruiker naar een nieuwe pagina met de output van de geconserveerde domeindatabase (CDD) van NCBI, die gedetailleerde informatie over het IL-8-domein biedt, met inbegrip van structurele informatie, meervoudige sequentieuitlijningen en beschrijvende informatie over het domein en de eiwitten die het bezitten.