o procedură automată scrisă în Microsoft Visual Basic (VB) 6.,0 actualizează DAVID weekly cu următoarele proceduri: apelați o serie de aplicații Perl și Java care descarcă date publice prin protocoale anonime de transfer de fișiere (FTP) (Tabelul 1); Despachetați și analizați datele de adnotare dorite; creați fișiere de date delimitate de file gata pentru importul bazei de date; și importați date într-un sistem de gestionare a bazelor de date relaționale Oracle 8i (RDBMS) folosind Serverul web IIE al Microsoft și tehnologia activă a paginii serverului sunt utilizate pentru a accesa baza de date folosind JavaBeans și limbajul de interogare structurat (SQL)., Numerele LocusLink pentru seturile de sonde Affymetrix sunt derivate din asociațiile Universității din Michigan sau NetAffx . Adnotările funcționale și referințele încrucișate ale bazei de date sunt derivate din LocusLink, care oferă reprezentări stabile, curate de om ale genelor. Pentru informații mai detaliate despre sursele de date utilizate de DAVID, consultați secțiunea Întrebări frecvente la .,
module de Analiza
DAVID este compus din patru module principale: Instrument de Adnotare, GoCharts, KeggCharts, și DomainCharts. Instrumentul de adnotare este o metodă automată pentru adnotarea funcțională a listelor de gene. Orice combinație de date de adnotare poate fi aleasă dintre 10 opțiuni selectând casetele de selectare corespunzătoare (Tabelul 2)., Adnotările sunt adăugate la lista de gene trimise prin selectarea butonului de încărcare, care returnează un tabel HTML care conține lista originală a identificatorilor utilizatorului anexată cu adnotările funcționale alese. Genele neanotate sunt incluse în ieșire fără date anexate în scopuri de urmărire.,
GoCharts modulul afișează grafic distribuția de gene diferit exprimate între categorii funcționale, folosind vocabularul controlat de Gene Ontology Consorțiu (DU-te), care oferă un mod structurat de limbaj care pot fi aplicate pentru funcțiile de gene și proteine în toate organismele chiar și cunoașterea continuă să se acumuleze și să se schimbe ., Limbajul este structurat într-un grafic aciclic direcționat (dag), în care specificitatea termenului crește și acoperirea genomului scade pe măsură ce se deplasează în jos în ierarhie. Spre deosebire de o ierarhie adevărată, termenii copilului într-un DAG pot avea mai mult de un termen părinte și pot avea o clasă diferită de relație cu părinții săi diferiți. Structura GO începe cu trei categorii principale, procesul biologic, funcția moleculară și componenta celulară., Procesul biologic include obiective biologice largi, cum ar fi mitoza sau metabolismul purinic, care sunt realizate prin ansambluri ordonate de funcții moleculare. Funcția moleculară descrie sarcinile efectuate de produse genetice individuale; exemple sunt factorul de transcripție și helicaza ADN. Tipul de clasificare a componentelor celulare implică structuri subcelulare, locații și complexe macromoleculare; exemplele includ nucleul, telomerul și complexul de recunoaștere a originii., După alegerea unui tip de clasificare, nivelurile care determină acoperirea și specificitatea listei sunt alese prin selectarea butonului radio corespunzător. Nivelul 1 oferă cea mai mare acoperire a listei cu cea mai mică cantitate de specificitate pe termen. Cu fiecare nivel de acoperire în creștere scade în timp ce specificitatea crește, astfel încât nivelul 5 oferă cea mai mică cantitate de acoperire cu cea mai mare specificitate pe termen.
datele de clasificare sunt afișate ca o diagramă cu bare, unde lungimea barei reprezintă numărul de identificatori de gene din fiecare categorie., Utilizatorul poate seta parametrii de vizualizare pentru sortarea datelor de ieșire și afișarea categoriilor care conțin cel puțin un număr minim de gene. Selectarea unei bare individuale deschide un nou tabel HTML care afișează identificatorul genei, Numărul LocusLink, numele genei, clasificarea curentă și alte clasificări pentru fiecare genă din acea categorie. Un buton ” Show All „deschide un nou tabel HTML care afișează toate datele de clasificare și un buton” Show Chart Data ” deschide un tabel HTML care conține datele grafice de bază, permițând astfel utilizatorilor să recreeze grafice grafice personalizate într-un program de calcul tabelar., O nouă diagramă poate fi afișată pentru orice subset de gene prin selectarea tipului și nivelului de clasificare folosind casetele de selectare și butoanele radio disponibile în pagina curentă a utilizatorului care permit capabilități de detaliere. Un număr al numărului de gene adnotate este inclus în ieșire, iar genele neanotate sunt incluse în categoria „neclasificate”, oferind astfel utilizatorilor un sistem automat de urmărire pentru genele care nu sunt adnotate.keggcharts afișează grafic distribuția genelor exprimate diferențiat între căile biochimice KEGG., Fiecare cale este legată de harta căii KEGG, în care genele exprimate diferențiat din lista inițială sunt evidențiate cu roșu. În acest sens, genele sunt legate în continuare de adnotări suplimentare disponibile prin intermediul sistemului de recuperare DBGET Kegg . Ca cu GoCharts, utilizatorul poate seta vizualizarea parametrilor de sortare a datelor de ieșire și afișarea categorii care conțin cel puțin un număr minim de gene și KeggCharts vizualizare moștenește toate caracteristicile dinamice ale GoCharts.
Domeniicharturile afișează distribuția genelor exprimate diferențiat între domeniile proteinei PFAM ., Fiecare denumire de domeniu este legată de baza de date a domeniului conservat (CDD) a Centrului Național pentru Informații Biotehnologice (NCBI), unde sunt disponibile imediat detalii privind funcția, structura și secvența domeniului. Ca cu GoCharts și KeggCharts, utilizatorul poate seta vizualizarea parametrilor de sortare a datelor de ieșire și afișarea categorii care conțin cel puțin un număr minim de gene și DomainCharts vizualizare moștenește toate caracteristicile dinamice ale GoCharts și KeggCharts. Pentru mai multe informații cu privire la funcționalitatea DAVID vizita secțiunea FAQ la .,pentru a demonstra funcționalitatea lui DAVID am analizat o listă de gene exprimate diferențiat în celulele mononucleare din sângele periferic uman (PBMCs) după incubarea cu proteine învelitoare HIV-1. Detalii experimentale, ARN de pregătire, și GeneChip hibridizare proceduri, împreună cu detaliile de la cip la cip normalizations și analiza statistică a diferențialului expresia genelor sunt prevăzute în Cicala et al. ., Pe scurt, Pbmc-urile umane primare și macrofagele derivate din monocite au fost incubate timp de 16 ore cu proteina învelișului HIV-1 (gp120). Microarrays oligonucleotide de înaltă densitate (Affymetrix Hu-95A GeneChip) au fost utilizate pentru a monitoriza evenimentele transcripționale induse de gp120. Această analiză a dus la identificarea a 402 gene exprimate diferențiat.în timp ce 16 gene modulate de HIV-1 gp120 au fost anterior asociate cu replicarea HIV și/sau semnalizarea plic, genele rămase sunt de funcție necunoscută sau nu au fost niciodată asociate cu HIV-1 sau gp120., Conversia acestei liste de gene în sens biologic necesită colectarea de informații pertinente din mai multe depozite de date. Pentru mulți cercetători, acest proces constă în navigarea iterativă prin mai multe baze de date pentru fiecare genă, colectând manual informații specifice genei privind secvența, funcția, calea și asocierea bolii. În schimb, abordarea sistematică a lui DAVID adaugă simultan informații bogate din punct de vedere biologic derivate din mai multe surse de date publice la listele de gene în paralel., Selectarea instrumentului de adnotare al lui DAVID și încărcarea listei de 402 gene exprimate diferențiat inițiază adnotarea funcțională și analiza întregului set de date. Odată trimisă, lista de gene este stocată pentru întreaga sesiune de analiză, permițând utilizatorilor să comute între module fără a fi nevoie să retrimită date.
instrument de adnotare
instrumentul de adnotare oferă mai multe opțiuni de adnotare și construiește o vedere tabelară a listei de gene a utilizatorilor și a adnotărilor disponibile (Tabelul 2)., Alegerea adnotare domenii Gene Simbol, LocusLink, OMIM, Unigene, de Referință Secvență, și Nume de Gene, urmată de selectarea butonul „Upload” produce un tabel HTML în browser-ul web care conține toate genele lor disponibile adnotări, în cazul în care gena identificatori, descriptiv și clasificare a datelor sunt scoase din baza de date și se anexează la gene listă (Figura 1). Gene de identificare, cum ar fi Gene Simbol și LocusLink sunt hyperlink suplimentare gene-date specifice disponibile la sursele originale, oferind astfel în profunzime gene-detalii specifice și adnotare pedigree., Datele de clasificare și rezumatele funcționale pot fi utilizate pentru a scana rapid informațiile relevante pentru sistemul experimental al cercetătorului. Timpul necesar pentru executarea acestui modul se corelează liniar cu mărimea listei de gene și durează mai puțin de 45 de secunde pentru listele de până la 1.000 de gene (Figura 2, Numerele din paranteze reprezintă valorile r2). Aceste rezultate demonstrează puterea și eficiența unei abordări integrate a adnotării funcționale a seturilor mari de date.,

Ouput de Instrument de Adnotare. Afișate sunt adnotări anexate pentru primele mai multe seturi de probe Affymetrix într-un tabel HTML care conține toate 402 intrări. Informații categorice despre condițiile experimentale au fost prezentate împreună cu identificatorii set-sondă Affymetrix și incluse în Ieșire în coloana valoare. De identificare, cum ar fi Simbol, LocusLink, OMIM, RefSeq, și Unigene aderări sunt hiper-legate de originea lor surse pentru informații mai detaliate., Textul inclus în câmpurile sumare este derivat din informațiile descriptive, funcționale furnizate în rapoartele LOCUSLINK ale NCBI.
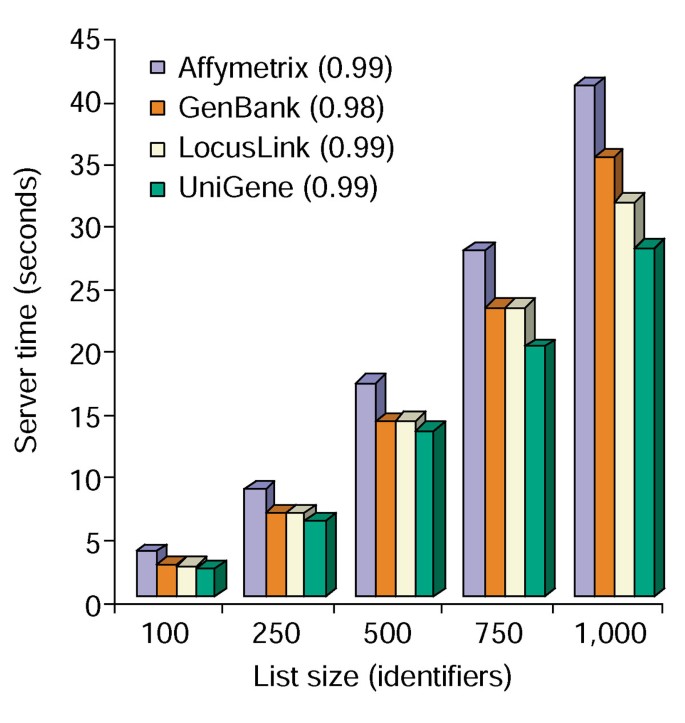
Timp de analiză de Instrument de Adnotare. Server de timp necesar (axa y) pentru a adăuga simultan toate cele 10 opțiuni de adnotare la liste de gene variind în mărime de la 100 la 1.000 (axa x)., Media a trei încercări pentru gene liste care conțin Affymetrix, GenBank, LocusLink, și UniGene de identificare sunt afișate și numerele din paranteze reprezintă r2 valoare de corelație între gene-lista de dimensiuni și serverul timpul necesar pentru adnotare.
GoCharts
Alegerea GoCharts modul deschide o fereastră nouă cu o varietate de opțiuni., Utilizatorii aleg între trei tipuri generale de clasificare (procesul biologic, funcția moleculară și componenta celulară) și cinci niveluri de adnotare care reprezintă acoperirea și specificitatea termenului (a se vedea secțiunea Module de analiză). Orice combinație de clasificare și nivel de acoperire poate fi specificată. De asemenea, sunt incluse opțiuni pentru adnotarea listelor de gene cu toți termenii GO disponibili sau doar cei mai specifici termeni, care sunt denumiți noduri terminale., Opțiunea de a alege diferite niveluri de specificitate pe termen oferă flexibilitatea necesară și, astfel, permite cercetătorilor să determine în mod dinamic ce nivel de acoperire și specificitate se potrivește cel mai bine datelor și stadiului lor de analiză. De exemplu, analizele în stadiu incipient pot consta în adnotarea listelor de gene cu termeni foarte generali pentru a obține o înțelegere largă a datelor. În acest caz, selectarea procesului biologic și nivelul 1 clasifică genele folosind termeni generali, cum ar fi „moartea” și „comunicarea celulară”., Utilizarea specificității sporite a termenului facilitează extragerea informațiilor funcționale mai detaliate. În acest caz, selectarea procesului biologic și nivelul 5 clasifică genele folosind termeni precum „modificări mitocondriale apoptotice”și” percepția chemosenzorială”.
cu toate acestea, specificitatea pe termen crescut vine un cost, în care, pe măsură ce crește acoperirea listei scade (Figura 3). În studiile noastre descoperim că nivelul 2 menține de obicei o acoperire bună, oferind în același timp o specificitate semnificativă pe termen., Figura 4a ilustrează modul în care Vizualizarea GoCharts dezvăluie rapid că 35 de gene exprimate diferențiat sunt implicate în „răspunsurile la stres”. Fiecare termen GO poate fi vizualizat în vizualizările tree sau DAG prin hyperlink-uri către QuickGO .
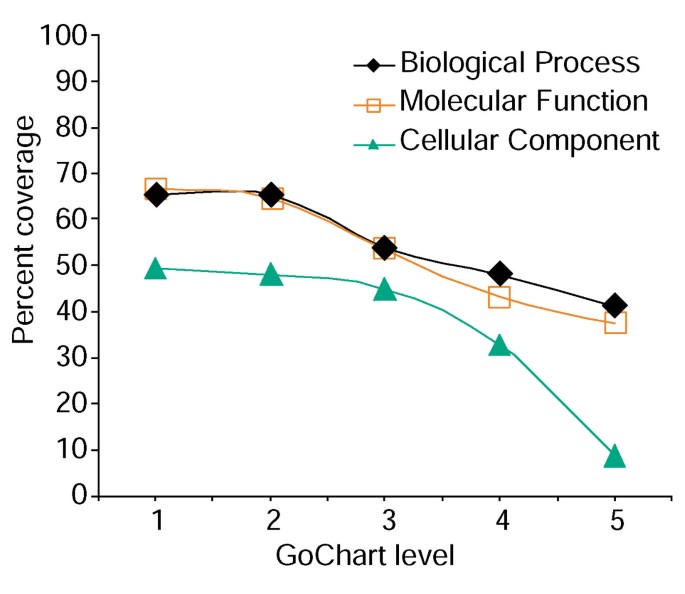
Analiză de gene-lista de acoperire folosind GoCharts. O listă de 402 identificatori ai setului de sonde Affymetrix au fost adnotați cu clasificările funcționale atribuite proteomului furnizate de LocusLink., Procentul de acoperire reprezintă numărul de gene din 402 care au fost adnotate la un nivel de specificitate a termenului în cadrul procesului biologic, funcției moleculare și tipurilor de clasificare a componentelor celulare. Procentul de acoperire scade odată cu creșterea specificității termenului.
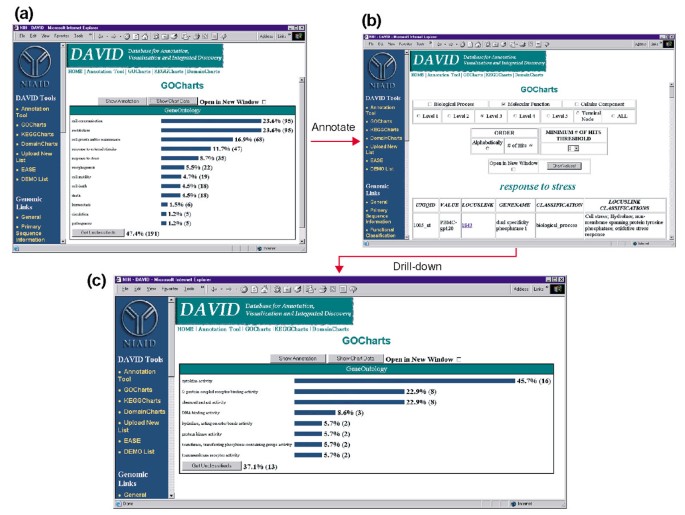
Ouput de GoCharts. (a) o diagramă cu bare care arată distribuția genelor exprimate diferențiat între procesele biologice de Ontologie genetică (GO)., Parametrii au fost setați pentru a merge nivelul 2, un prag de succes de cinci, și de ieșire a fost sortat de numărul de hit. Barele albastre sunt legate de datele suplimentare de adnotare prezentate la litera (b). Selectarea barei albastre din (a) corespunzătoare „răspunsului la stres” deschide un tabel HTML care prezintă LocusLink-ul, numele genei, clasificarea curentă și alte date de clasificare pentru genele din acea categorie. (c) acest subset de gene implicate în „răspunsul la stres” a fost caracterizat în continuare prin selectarea funcției moleculare GO, GO level 3, un prag de succes de 2 și sortat după numărul de lovituri., Selectarea butonului „Chart Values” creează o nouă histogramă care arată că 16 din cele 35 de gene de răspuns la stres codifică proteine cu activitate citokină.,
Pentru HIV-1 are un impact major asupra funcției de celule ale sistemului imunitar și capacitatea lor de a efectua reacții de stres, am selectat histograma bar, reprezentând numărul de gene implicate în răspunsul la stres, care se deschide un tabel HTML care conține Affymetrix de identificare, LocusLink număr, nume de gene, clasificarea actuală, și alte clasificări pentru toate cele 35 de gene (Figura 4b)., Acum că ne-am redus lista de gene la acele gene implicate în răspunsurile la stres, am caracterizat în continuare acest subset prin repetarea procedurii GoCharts disponibile în partea de sus a tabelului HTML de răspuns la stres. Alegerea funcției moleculare, nivelul 3 produce o nouă histogramă care dezvăluie rapid că aproape jumătate (16/35) din genele de răspuns la stres posedă activitate citokină (figura 4c)., Într-adevăr, s-a demonstrat că citokinele joacă un rol important în ciclul de viață HIV-1, iar rezultatele obținute aici sugerează că tratamentul PBMCs cu proteine plic HIV-1 modulează semnificativ transcripția a numeroase gene citokine. Eficiența cu care GoCharts a rezumat sistematic acest set mare de date cu vizualizări grafice, rămânând în același timp legată de datele primare și resursele externe a îmbunătățit drastic procesul de descoperire.,
KeggCharts
Figura 5a descrie ieșire de KeggCharts cu o histogramă afișează distribuția de gene diferit exprimate între căile biochimice. Graficul arată că o cale KEGG de apoptoză include cinci gene induse de HIV-1 gp120. Selectarea numelui căii deschide harta corespunzătoare a căii biochimice Kegg și evidențiază în contur roșu genele exprimate diferențiat care funcționează pe acea cale (figura 5b). În acest sens, genele sunt legate în continuare de adnotări suplimentare disponibile prin intermediul sistemului de recuperare DBGET Kegg ., Rețineți că doar patru gene din calea apoptozei KEGG sunt evidențiate în roșu, în timp ce instrumentul KeggCharts a cartografiat cinci seturi de sonde Affymetrix pe calea apoptozei. Această diferență se datorează faptului că două dintre sondele Affymetrix vizează aceeași genă „TNF-alfa”.
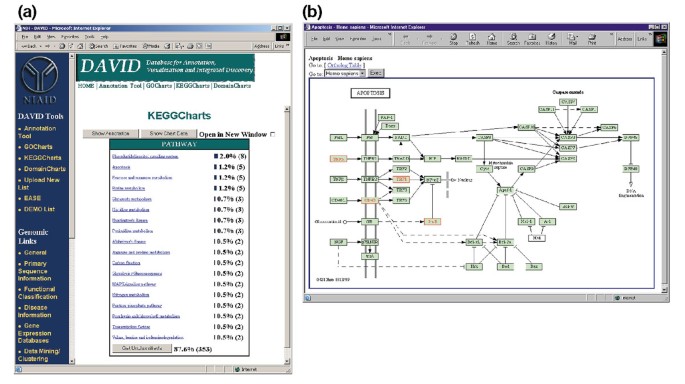
Ouput de KeggCharts. (a) diagrama de vizualizare care arată distribuția a 402 gene între căile biochimice Kegg. Pragul de succes a fost setat la trei, iar rezultatul a fost sortat după numărul de lovituri., Numărul mare de identificatori neclasificați se datorează faptului că KEGG este centrat pe calea biochimică și oferă astfel o acoperire redusă a listelor de gene. Similar cu producția de GoCharts, barele albastre reprezintă numărul de gene din fiecare cale. Selectarea unei bare albastre deschide un tabel HTML care arată LocusLink, numele genei, clasificarea curentă și alte date de clasificare pentru genele din acea cale (datele nu sunt prezentate)., (b) calea biochimică KEGG care apare în urma selecției numelui căii „apoptoză” din (A) prezintă patru gene exprimate diferențiat în calea apoptozei, evidențiindu-le în verde deschis și roșu. Faptul că KEGG cale evidențiază doar patru gene întrucât KeggChart hărți cinci Affymetrix sonda seturi la apoptoza cale se datorează faptului că două probe seturi țintă același „TNF-alpha” de gene.,
DomainCharts
DomainCharts din punct de vedere operațional sunt asemănătoare la ambele KeggCharts și GoCharts, cu excepția faptului că rezultatele vizual reprezentând distribuirea de gene între PFAM proteine domenii (Figura 6a). Histograma DomainCharts identifică 16 gene cu domenii de kinază (pkinază), reflectând probabil efectele gp120 HIV-1 asupra echipamentului de transducție a semnalului. Diagrama identifică, de asemenea, șase gene cu domenii interleukină-8 (IL-8), un domeniu care reprezintă un motiv foarte conservat printre citokinele cu răspuns la stres., Selectarea numelui de domeniu ” IL8 ” deschide pagina bazei de date de domenii conservate (CDD) corespunzătoare domeniului PFAM respectiv (figura 6b). Această pagină oferă secvențe detaliate, structură și informații funcționale despre domeniul IL-8 și proteinele care îl conțin.
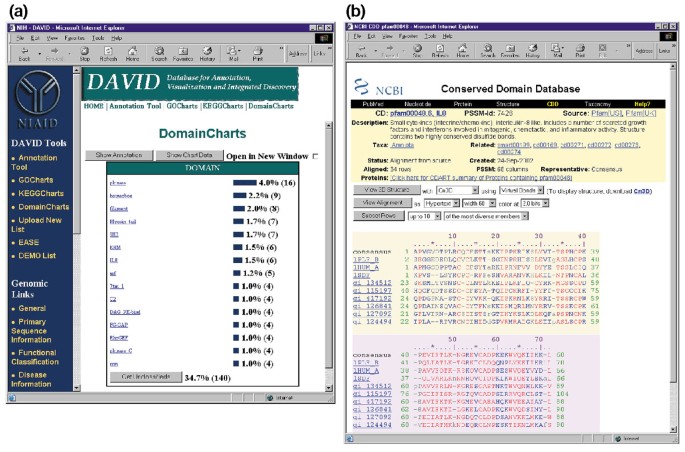
Ouput de DomainCharts. (a) diagrama de vizualizare care arată distribuția a 402 gene între domeniile proteice. Parametrii au fost setați la un prag minim de lovire de patru, iar ieșirea a fost sortată după numărul de lovituri., Similar cu producția de GoCharts și KeggCharts, barele albastre reprezintă numărul de gene care conțin acel domeniu particular. Selectarea unei bare albastre deschide un tabel HTML care arată LocusLink, numele genei, clasificarea curentă și alte date de clasificare pentru genele din acea cale (datele nu sunt prezentate)., (b) Selectarea numelui de domeniu „IL8” în (a), care conține șase gene diferit exprimate, aduce utilizatorul la o pagină nouă care conține ieșire din Conservate Domeniu de baze de Date (CDD) din NCBI, care oferă informații detaliate despre IL-8 domeniu, inclusiv informații structurale, mai multe secvență aliniamente, și informații descriptive despre domeniu și proteinele pe care le posedă.