automatizovaný postup napsaný v Microsoft Visual Basic (VB) 6.,0 DAVID týdenní aktualizace s následující postupy: volání sérii Perl a Java aplikace ke stažení veřejné dat přes anonymní přenos souborů protokoly (FTP) (Tabulka 1); rozbalit a analyzovat požadované anotace dat; vytvořit oddělený tabulátory formátu datové soubory, a připraven pro databáze import; a importovat data do Oracle 8i relační databáze systém vedení (RDBMS) pomocí Oracle“s SQL*Loader aplikace. Pro přístup k databázi pomocí JavaBeans a structured query language (SQL) se používá webový server společnosti Microsoft IIE a technologie Active Server Page., Čísla LocusLink pro sady sond Affymetrix jsou odvozena od asociací University of Michigan nebo NetAffx . Funkční anotace a databázové křížové odkazy jsou odvozeny od LocusLink, který poskytuje stabilní, lidské kurátorské reprezentace genů. Podrobnější informace o zdrojích dat používaných Davidem naleznete v sekci FAQ na adrese .,
Analýza moduly
DAVID se skládá ze čtyř hlavních modulů: Anotace Nástroj, GoCharts, KeggCharts, a DomainCharts. Anotační nástroj je automatizovaná metoda pro funkční anotaci genových seznamů. Libovolnou kombinaci anotačních dat lze vybrat z 10 možností výběrem příslušných zaškrtávacích políček (Tabulka 2)., Anotace jsou přidány do předloženého seznamu genů výběrem tlačítka Nahrát, který vrací tabulku HTML obsahující původní seznam identifikátorů uživatele připojených k vybraným funkčním anotacím. Na výstupu jsou zahrnuty neanotované geny bez připojených dat pro účely sledování.,
GoCharts modul graficky zobrazí rozložení rozdílně vyjádřené genů mezi funkční kategorií pomocí řízeného slovníku z Gene Ontology Consortium (JÍT), který poskytuje strukturovaný jazyk, který může být aplikován na funkce genů a proteinů ve všech organismech i jako znalosti nadále hromadit a měnit ., Jazyk je strukturován v režii acyklický graf (DAG), přičemž termín specifičnost zvyšuje a pokrytí genomu klesá jako jeden se pohybuje směrem dolů hierarchií. Na rozdíl od skutečné hierarchie, podmínky dítěte v DAG mohou mít více než jeden rodičovský termín a mohou mít jinou třídu vztahu se svými různými rodiči. Struktura GO začíná třemi hlavními kategoriemi, biologickým procesem, molekulární funkcí a buněčnou složkou., Biologický proces zahrnuje široké biologické cíle, jako je mitóza nebo purinový metabolismus, které jsou prováděny uspořádanými sestavami molekulárních funkcí. Molekulární funkce popisuje úkoly prováděné jednotlivými genovými produkty; příklady jsou transkripční faktor a DNA helikáza. Typ klasifikace buněčné složky zahrnuje subcelulární struktury, umístění a makromolekulární komplexy; příklady zahrnují jádro, telomer a komplex rozpoznávání původu., Po výběru typu klasifikace jsou úrovně, které určují pokrytí a specifičnost seznamu, vybrány výběrem příslušného tlačítka rádia. Úroveň 1 poskytuje nejvyšší pokrytí seznamu s nejmenším množstvím termínové specifičnosti. S každým zvyšujícím se pokrytím úrovně se snižuje, zatímco specificita se zvyšuje, takže úroveň 5 poskytuje nejmenší množství pokrytí s nejvyšší termínovou specificitou.
klasifikační data jsou zobrazena jako čárový graf, kde délka lišty představuje počet identifikátorů genů v každé kategorii., Uživatel může nastavit vizualizační parametry pro třídění výstupních dat a zobrazení kategorií, které obsahují alespoň minimální počet genů. Výběrem jednotlivé lišty se otevře nová tabulka HTML zobrazující identifikátor genu, číslo LocusLink, název genu, aktuální klasifikaci a další klasifikace pro každý gen v této kategorii. Tlačítko “ Zobrazit vše „otevře novou tabulku HTML zobrazující všechna klasifikační data a tlačítko“ Zobrazit data grafu “ otevře tabulku HTML obsahující základní data grafu, což uživatelům umožní znovu vytvořit přizpůsobenou grafickou grafiku v tabulkovém programu., Nový graf lze zobrazit pro jakoukoli podmnožinu genů výběrem typu klasifikace a úrovně pomocí zaškrtávacích políček a rádiových tlačítek dostupných na aktuální stránce uživatele, které umožňují možnosti drill-down. Počet genů komentovaný je součástí výstupu a unannotated geny jsou vykázáni do „nezařazené“ kategorie, čímž poskytuje uživatelům automatizovaný systém sledování pro geny nejsou komentovaný.
KeggCharts graficky zobrazují distribuci diferenciálně exprimovaných genů mezi Kegg biochemickými cestami., Každá cesta je spojena s mapou dráhy KEGG, kde jsou odlišně exprimované geny z původního seznamu zvýrazněny červeně. V tomto pohledu jsou geny dále spojeny s dalšími anotacemi dostupnými prostřednictvím systému Kegg dbget retrieval system . Jako s GoCharts, může uživatel nastavit vizualizace parametrů pro třídění výstupních dat a zobrazování kategorií, které obsahují alespoň minimální počet genů a KeggCharts vizualizace dědí všechny dynamické vlastnosti GoCharts.
DomainCharts zobrazují distribuci diferenciálně exprimovaných genů mezi pfam proteinovými doménami ., Každá doména označení je spojeno s Conserved Domain Database (CDD) Národního Centra pro Biotechnologické Informace (NCBI), kde jsou podrobnosti o doméně funkce, struktura a sekvence jsou snadno dostupné. Jako s GoCharts a KeggCharts, může uživatel nastavit vizualizace parametrů pro třídění výstupních dat a zobrazování kategorií, které obsahují alespoň minimální počet genů a DomainCharts vizualizace dědí všechny dynamické vlastnosti GoCharts a KeggCharts. Další informace týkající se funkčnosti Davida naleznete v sekci FAQ na adrese .,
Použití DAVID dolu funkční anotace
prokázat funkčnost DAVID analyzovali jsme seznam genů odlišně vyjádřené v lidských periferních krevních mononukleárních buněk (Pbmc) po inkubaci HIV-1 obálka proteiny. Podrobnosti o experimentální, RNA, příprava a GeneChip hybridizace procedury, spolu s údaji o chip-to-chip číslo normalizations a statistické analýzy diferenciální genové exprese jsou uvedeny v Cicala et al. ., Stručně řečeno, primární lidské pbmc a makrofágy odvozené od monocytů byly inkubovány po dobu 16 hodin s HIV-1 obálkovým proteinem (gp120). High-density oligonukleotidových mikročipů (Affymetrix HU-95A GeneChip) byly použity k monitorování gp120-indukované transkripční události. Tato analýza vedla k identifikaci 402 odlišně exprimovaných genů.
zatímco 16 genů modulovaných HIV-1 gp120 bylo dříve spojeno s replikací HIV a / nebo signalizací obálky, zbývající geny mají neznámou funkci nebo nikdy nebyly spojeny s HIV-1 nebo gp120., Převedení tohoto seznamu genů do biologického významu vyžaduje shromažďování příslušných informací z několika datových úložišť. Pro mnoho vědců se tento proces skládá z iterativního procházení několika databází pro každý gen, manuálního shromažďování informací specifických pro Gen, pokud jde o sekvenci, funkci, cestu a asociaci nemocí. Naproti tomu systematický přístup Davida současně přidává biologicky bohaté informace získané z několika veřejných datových zdrojů do seznamů genů paralelně., Výběr nástroje pro anotaci Davida a nahrání seznamu 402 diferenciálně exprimovaných genů iniciuje funkční anotaci a analýzu celého souboru dat. Po odeslání je seznam genů uložen pro celou relaci analýzy, což uživatelům umožňuje přepínat mezi moduly, aniž by museli znovu zadávat data.
Nástroj pro anotaci
Nástroj pro anotaci poskytuje několik možností anotace a vytváří tabulkové zobrazení seznamu genů uživatelů a dostupných anotací (Tabulka 2)., Výběr anotace oblastech Genu Symbol, LocusLink, OMIM, Unigene, Referenční Sekvence a Gen Jméno následuje volba „Nahrát“ tlačítko, vytvoří HTML tabulku ve webovém prohlížeči, které obsahují všechny geny a jejich k dispozici popisy, kde gen identifikátory, popisné a klasifikační data jsou vytáhl z databáze a připojen ke genu seznamu (Obrázek 1). Gen identifikátory, jako jsou Genové Symbol a LocusLink jsou hypertextovými odkazy na další gen-konkrétní údaje jsou k dispozici na jejich původní zdroje, což poskytuje in-hloubkové gen-konkrétní detaily a anotace rodokmeny., Klasifikační data a funkční souhrny mohou být použity k rychlému skenování informací relevantních pro experimentální systém výzkumníka. Serveru čas potřebný k provedení tohoto modulu lineárně koreluje s velikostí genu seznam a trvá méně než 45 sekund, uvádí až 1000 genů (Obrázek 2, čísla v závorkách představují hodnoty r2). Tyto výsledky demonstrují sílu a účinnost integrovaného přístupu k funkční anotaci velkých datových souborů.,

Výstup Anotace Nástroj. Zobrazeny jsou přiložené anotace pro prvních několik sad Affymetrix sondy v HTML tabulce obsahující všech 402 položek. Kategorické informace o experimentálních podmínkách byly předloženy spolu s identifikátory sady sond Affymetrix a zahrnuty do výstupu ve sloupci hodnota. Identifikátory, jako Symbol, LocusLink, OMIM, RefSeq, a Unigene přistoupení jsou hyper-vázáno na jejich původ zdroje pro podrobnější informace., Text obsažený v souhrnných polích je odvozen z popisných, funkčních informací poskytovaných ve zprávách LocusLink NCBI.
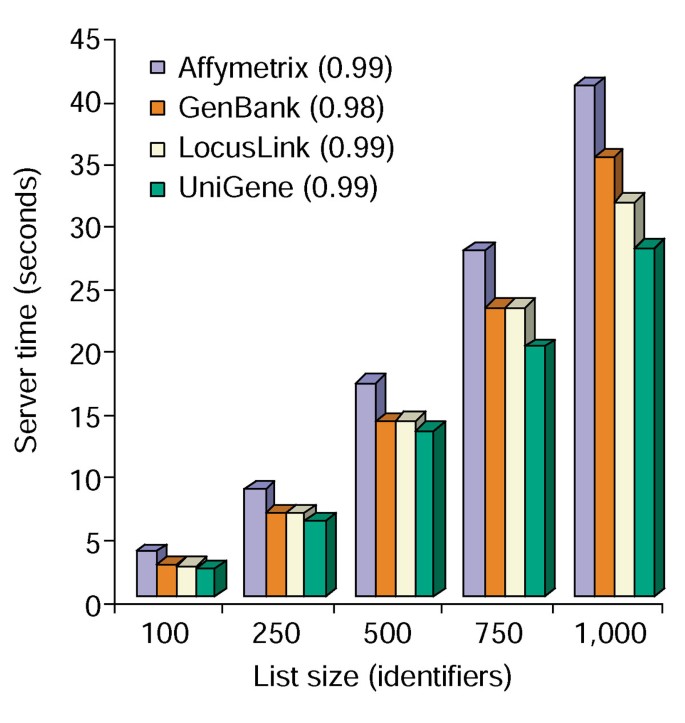
Time analýzy Anotace Nástroj. Server čas potřebný (osa y) současně připojit všech 10 možností anotace do genových seznamů v rozsahu od 100 do 1000 (osa x)., Průměr ze tří zkoušek na genové seznamy obsahující Affymetrix, GenBank, LocusLink, a UniGene identifikátory jsou uvedeny a čísla v závorkách představují r2 hodnota korelace mezi gen-velikost seznamu a server doba potřebná pro anotace.
GoCharts
Výběr GoCharts modulu se otevře nové okno s různými možnostmi., Uživatelé si vybrat mezi tři obecné typy klasifikace (biologické procesy, molekulární funkce, buněčné komponenty) a pět úrovní anotace, které představují dlouhodobé pokrytí a specifičnost (viz Analýza Modulů sekce). Může být specifikována jakákoli kombinace klasifikace a úrovně pokrytí. Zahrnuty jsou také možnosti anotace seznamů genů se všemi dostupnými termíny GO nebo pouze nejkonkrétnějšími termíny, které jsou označovány jako terminálové uzly., Možnost zvolit různé úrovně termín specificita poskytuje potřebnou flexibilitu a umožňuje tak vědci dynamicky určit, která úroveň pokrytí a specifičnost nejlépe vyhovuje jejich dat a fázi analýzy. Například analýzy v rané fázi mohou sestávat z anotace seznamů genů s velmi obecnými termíny,aby bylo možné získat široké pochopení dat. V tomto případě výběr biologického procesu a úroveň 1 klasifikuje geny pomocí obecných termínů, jako je „smrt“ a „buněčná komunikace“., Použití zvýšené termínové specificity usnadňuje extrakci podrobnějších funkčních informací. V tomto případě výběr biologického procesu a úroveň 5 klasifikuje geny pomocí termínů jako“ apoptotické mitochondriální změny „a“chemosenzorické vnímání“.
zvýšená termínová specificita však představuje náklady, protože zvyšuje pokrytí seznamu (obrázek 3). V našich studiích zjistíme, že úroveň 2 obvykle udržuje dobré pokrytí a zároveň poskytuje smysluplnou termínovou specifičnost., Obrázek 4a ukazuje, jak vizualizace GoCharts rychle odhaluje, že 35 odlišně exprimovaných genů se podílí na“stresových reakcích“. Každý termín GO lze zobrazit ve stromu nebo zobrazení DAG pomocí hypertextových odkazů na QuickGO .
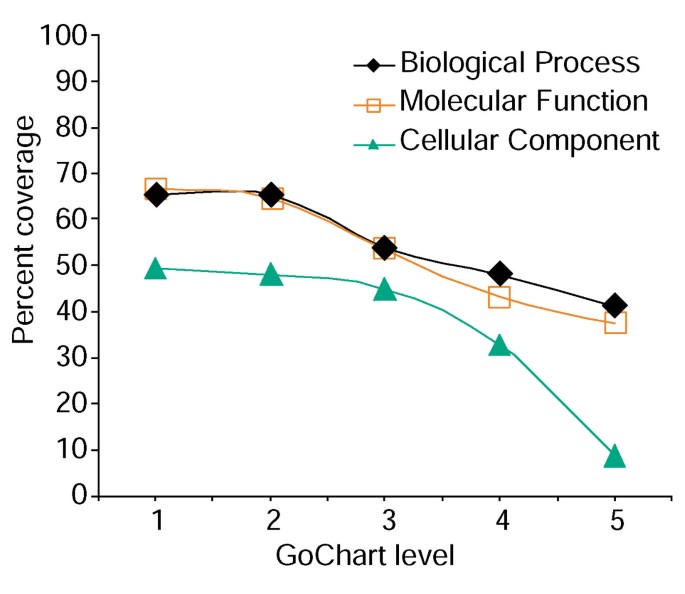
Analýza genu-seznam pokrytí pomocí GoCharts. Seznam 402 Affymetrix probe set identifikátory jsou komentovaný s Proteomu přiřazeny funkční klasifikace poskytována LocusLink., Procenta pokrytí představuje počet genů z 402, které byly anotovány na termín-specifičnost úrovni v rámci Biologické procesy, Molekulární Funkce, Buněčné Součásti, typy klasifikace. Procento pokrytí klesá s rostoucí termínovou specificitou.
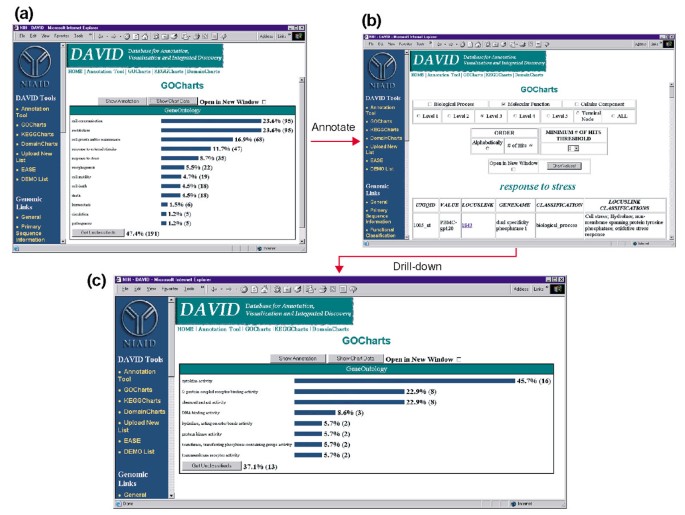
Výstup z GoCharts. (a) čárový graf ukazující distribuci diferenciálně exprimovaných genů mezi genovou ontologií (GO) biologickými procesy., Parametry byly nastaveny na úroveň 2, práh hitu pěti a výstup byl seřazen podle počtu zásahů. Modré pruhy jsou spojeny s dalšími anotačními údaji uvedenými v písmenu b). Výběr modrý pruh v (a), odpovídající „reakce na stres“, otevře se HTML tabulku LocusLink, gen jméno, aktuální klasifikace a ostatní klasifikační data pro geny v této kategorii. (c) tato podmnožina genů zapojených do „stresové odpovědi“ byla dále charakterizována výběrem molekulární funkce GO, úrovně GO 3, prahové hodnoty hit 2 a seřazené podle počtu zásahů., Výběrem tlačítka „hodnoty grafu“ se vytvoří nový histogram, který odhalí, že 16 z 35 genů stresové reakce kóduje proteiny, které mají cytokinovou aktivitu.,
Protože HIV-1 má zásadní vliv na funkci buněk imunitního systému a jejich schopnost provádět reakce na stres, jsme vybrali histogram bar představující počet genů zahrnutých v odpovědi na stres, který otevírá HTML tabulky obsahující Affymetrix identifikátor, LocusLink číslo, název gene, současná klasifikace, a jiné klasifikace pro všech 35 genů (Obrázek 4b)., Nyní, když jsme snížili náš seznam genů na ty geny zapojené do stresových reakcí,jsme tuto podmnožinu dále charakterizovali opakováním postupu GoCharts dostupného v horní části tabulky HTML odpovědi na stres. Výběr molekulární funkce, úroveň 3 vytváří nový histogram, který rychle odhalí, že téměř polovina (16/35) stres-odpověď geny mají cytokinové aktivity (Obrázek 4c)., Opravdu, cytokiny bylo prokázáno, že hrají důležitou roli v HIV-1 životní cyklus a získané výsledky naznačují, že léčba Pbmc s HIV-1 obálka proteiny významně moduluje transkripci mnoha cytokinů geny. Účinnost, se kterou GoCharts systematicky shrnul tento velký datový soubor s grafickými vizualizacemi, zatímco zůstal spojen s primárními daty a externími zdroji, drasticky zlepšil proces objevování.,
KeggCharts
Obrázek 5a zobrazuje výstup KeggCharts s histogram zobrazující rozložení rozdílně vyjádřené genů mezi biochemické dráhy. Graf ukazuje, že cesta apoptózy KEGG zahrnuje pět genů indukovaných HIV-1 gp120. Výběrem názvu dráhy se otevře odpovídající Kegg biochemická cesta mapa a zvýrazní červeně načrtnout diferenciálně exprimované geny fungující v této cestě (obrázek 5b). V tomto pohledu jsou geny dále spojeny s dalšími anotacemi dostupnými prostřednictvím systému Kegg dbget retrieval system ., Všimněte si, že pouze čtyři geny v dráze apoptózy KEGG jsou zvýrazněny červeně, zatímco nástroj KeggCharts mapoval pět sad Affymetrix sondy na apoptózu. Tento rozdíl je způsoben skutečností, že dva z affymetrixových sondů se zaměřují na stejný gen „TNF-alfa“.
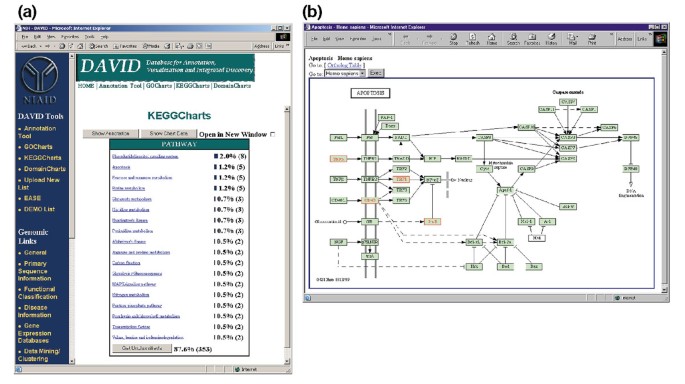
Výstup z KeggCharts. (a) vizualizační graf ukazující rozdělení 402 genů mezi biochemické dráhy KEGG. Práh zásahu byl nastaven na tři a výstup byl řazen podle počtu zásahů., Velký počet nezařazených identifikátorů je způsoben skutečností, že KEGG je centrická biochemická dráha a poskytuje tak nízké pokrytí seznamů genů. Podobně jako výstup GoCharts, modré pruhy představují počet genů v každé cestě. Výběr modrého pruhu otevře tabulku HTML zobrazující LocusLink, název genu, aktuální klasifikaci a další klasifikační data pro geny v této cestě (data nejsou zobrazena)., (b) KEGG biochemickou cestu, která se zobrazí po výběru cesty názvem „apoptóza“ v (a) zachycuje čtyři rozdílně vyjádřené genů v rámci apoptózy cestou zvýraznění je v světle zelené a červené. Skutečnost, že cesta KEGG zdůrazňuje pouze čtyři geny, zatímco keggchart mapuje pět sad Affymetrix sondy na apoptózu, je způsobena skutečností, že dvě sady sond se zaměřují na stejný gen „TNF-alfa“.,
DomainCharts
DomainCharts jsou funkčně podobný jak KeggCharts a GoCharts, kromě toho, že výsledky vizuálně zobrazující rozložení genů mezi PFAM proteinových domén (Obrázek 6a). Na DomainCharts histogram identifikuje 16 genů s kinázy domén (pkinase), což pravděpodobně odráží účinků HIV-1 gp120 na signální transdukci stroje. Graf také identifikuje šest genů s doménami interleukin-8 (IL-8), doménou, která představuje vysoce konzervovaný motiv mezi cytokiny reakce na stres., Výběrem názvu domény “ IL8 “ se otevře stránka Conserved Domain Database (CDD) odpovídající této doméně PFAM (obrázek 6b). Tato stránka poskytuje detailní sekvenci, strukturu a funkční informace o doméně IL-8 a bílkovinách, které ji obsahují.
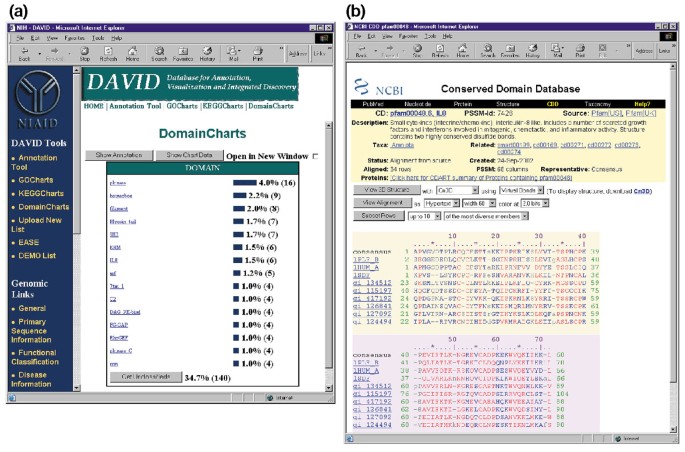
Výstup z DomainCharts. (a) vizualizační graf ukazující rozdělení 402 genů mezi proteinové domény. Parametry byly nastaveny na minimální prahovou hodnotu pro čtyři a výstup byl seřazen podle počtu zásahů., Podobně jako výstup GoCharts a KeggCharts, modré pruhy představují počet genů obsahujících tuto konkrétní doménu. Výběr modrého pruhu otevře tabulku HTML zobrazující LocusLink, název genu, aktuální klasifikaci a další klasifikační data pro geny v této cestě (data nejsou zobrazena)., (b) Výběru název domény „IL8“ v (a), které obsahuje šest rozdílně vyjádřené geny, přináší uživateli novou stránku obsahující výstup z Conserved Domain Database (CDD) z NCBI, která poskytuje podrobné informace o IL-8 domény, včetně informací o struktuře, více sekvence zarovnání, a popisné informace o doméně a proteinů, které mají to.