an automated procedure written in Microsoft Visual Basic (VB) 6.,0 frissíti DAVID weekly a következő eljárások: hívjon egy sor Perl és Java alkalmazások letölthető nyilvános adatok névtelen fájlátviteli protokollok (FTP) (1. táblázat); kicsomagolni és elemezni kívánt annotációs adatok; hozzon létre tab-körülhatárolt adatfájlokat kész adatbázis import; és importálja az adatokat egy Oracle 8i relációs adatbázis-kezelő rendszer (RDBMS) segítségével Oracle s SQL*Loader alkalmazás. A Microsoft IIE webszerver és az Active Server Page technológiát használják az adatbázis eléréséhez JavaBeans és a strukturált lekérdezési nyelv (SQL) segítségével., LocusLink számok Affymetrix szonda készletek származnak University of Michigan egyesületek vagy NetAffx . A funkcionális annotációk és adatbázis-kereszthivatkozások a LocusLink-ből származnak, amely a gének stabil, ember-kurált ábrázolását biztosítja. A DAVID által használt adatforrásokkal kapcsolatos részletesebb információkért lásd a GYIK részt .,
elemzési modulok
DAVID négy fő modulból áll: Annotation Tool, GoCharts, KeggCharts, and DomainCharts. Az annotációs eszköz egy automatizált módszer a génlisták funkcionális annotációjára. Az annotációs adatok bármilyen kombinációja 10 lehetőség közül választható ki a megfelelő jelölőnégyzetek kiválasztásával (2.táblázat)., Az annotációk adunk a benyújtott gén lista kiválasztásával a feltöltés gomb, amely visszaadja a HTML táblázatot, amely a felhasználó eredeti azonosítók listáját csatolt a kiválasztott funkcionális kommentárok. A nem jelölt gének szerepelnek a kimeneten, Nincs csatolt adat követési célokra.,
a GoCharts modul grafikusan jeleníti meg a differenciálisan expresszált gének eloszlását a funkcionális kategóriák között, a gén ontológiai konzorcium (GO) ellenőrzött szókincsét használva, amely olyan strukturált nyelvet biztosít, amely alkalmazható a a gének és fehérjék funkciói minden szervezetben, még akkor is, ha a tudás továbbra is felhalmozódik és megváltozik., A nyelv egy irányított aciklikus gráfban (DAG) van felépítve, ahol a kifejezés specifikussága növekszik, a genom lefedettsége pedig csökken, ahogy az egyik lefelé mozog a hierarchiában. A valódi hierarchiával ellentétben a DAG-ban a gyermekfogalmaknak egynél több szülői kifejezése lehet, és eltérő osztályú kapcsolatuk lehet a különböző Szülőkkel. A GO szerkezete három fő kategóriával, biológiai folyamattal, molekuláris funkcióval és Sejtkomponenssel kezdődik., A biológiai folyamat magában foglalja a széles biológiai célokat, például a mitózist vagy a purin anyagcserét, amelyeket molekuláris funkciók rendezett egységei hajtanak végre. A molekuláris függvény az egyes géntermékek által végzett feladatokat írja le; erre példa a transzkripciós faktor és a DNS helikáz. A sejtkomponens osztályozási típusa szubcelluláris struktúrákat, lokalizációkat és makromolekuláris komplexeket foglal magában; ilyenek például a sejtmag, a telomere és az eredetfelismerő komplex., A besorolási típus kiválasztása után a lista lefedettségét és specifikusságát meghatározó szinteket a megfelelő rádió gomb kiválasztásával választjuk ki. Level 1 biztosítja a legmagasabb lista lefedettség a legkisebb mennyiségű kifejezés specificitás. Minden növekvő szintű lefedettség csökken, míg a specifitás növekszik, így az 5. szint biztosítja a legkevesebb lefedettséget a legmagasabb kifejezéssel.
osztályozási adatok sávdiagramként jelennek meg, ahol a sáv hossza az egyes kategóriák génazonosítóinak számát jelöli., A felhasználó megjelenítési paramétereket állíthat be a kimeneti adatok válogatásához, valamint olyan kategóriák megjelenítéséhez, amelyek legalább minimális számú gént tartalmaznak. Az egyes sávok kiválasztásával megnyílik egy új HTML-táblázat, amely megjeleníti a génazonosítót, a LocusLink számot, a génnevet, az aktuális osztályozást és az adott kategória egyes génjeinek egyéb osztályozását. A “Show All” gombra, megnyílik egy új HTML táblázat jelenít meg az összes besorolási adat, valamint egy “Show Diagram Adatok” gombra kattintva megnyílik egy HTML táblázat, amely a diagram alapjául szolgáló adatok, így lehetővé téve a felhasználók számára, hogy újra szabott diagram, grafika a táblázatban program., Egy új diagram megjeleníthető bármely részhalmaza gének kiválasztásával a besorolás típusa és szintje a jelölőnégyzetek és rádió gombok belül elérhető a felhasználó aktuális oldal, amely lehetővé teszi a fúró-le képességeit. Az annotált gének számának számozása szerepel a kimeneten, a nem jelölt géneket pedig a “nem osztályozott” kategóriába sorolják, így a felhasználók számára automatizált nyomkövető rendszert biztosítanak a nem kommentált gének számára.
a KeggCharts grafikusan mutatja a különböző expresszált gének eloszlását a KEGG biokémiai utak között., Minden út kapcsolódik a KEGG útvonal térkép, ahol különbözőképpen expresszált gének az eredeti lista pirossal van kiemelve. Ebben a nézetben a gének tovább kapcsolódnak a KEGG”s DBGET visszakeresési rendszerén keresztül elérhető további megjegyzésekhez . A Gochartshoz hasonlóan a felhasználó megjelenítési paramétereket is beállíthat a kimeneti adatok rendezéséhez, valamint olyan kategóriák megjelenítéséhez, amelyek legalább minimális számú gént tartalmaznak, a KeggCharts vizualizáció pedig örökli a GoCharts összes dinamikus jellemzőjét.
A DomainCharts a különböző expresszált gének eloszlását mutatja A PFAM fehérje domének között ., Minden domain kijelölés kapcsolódik a National Center for Biotechnology Information (NCBI) megőrzött Domain adatbázisához (CDD), ahol a domain funkcióra, struktúrára és sorrendre vonatkozó részletek könnyen elérhetők. A Gochartshoz és a Keggchartshoz hasonlóan a felhasználó megjelenítési paramétereket is beállíthat a kimeneti adatok rendezéséhez, valamint olyan kategóriák megjelenítéséhez, amelyek legalább minimális számú gént tartalmaznak, a DomainCharts vizualizáció pedig örökli a GoCharts és a KeggCharts összes dinamikus jellemzőjét. A DAVID működésével kapcsolatos további információkért látogasson el a GYIK szakaszba .,
David használatával a funkcionális annotáció bányászatához
DAVID funkcionalitásának bizonyítására elemeztük a humán perifériás vér mononukleáris sejtekben (PBMCs) eltérő módon expresszált gének listáját a HIV-1 boríték fehérjékkel történő inkubálás után. A kísérleti, RNS-előkészítő és GeneChip-hibridizációs eljárások részleteit, valamint a chip-to-chip normalizációk részleteit, valamint a differenciál génexpresszió statisztikai elemzését Cicala et al. ., Röviden, Az elsődleges humán Pbmc-ket és a monocita eredetű makrofágokat 16 órán keresztül inkubáltuk HIV-1 boríték fehérjével (gp120). Nagy sűrűségű oligonukleotid mikroarrays (Affymetrix HU-95A GeneChip) a gp120 által indukált transzkripciós események monitorozására használták. Ez az elemzés 402 különböző expresszált gén azonosítását eredményezte.
Mivel 16 gének árnyalja a HIV-1 gp120 korábban a HIV replikáció és/vagy a boríték jelzés, a fennmaradó gének az ismeretlen függvény, vagy még soha nem volt a HIV-1 vagy gp120., A gének ezen listájának biológiai jelentéssé történő átalakítása megköveteli a vonatkozó információk összegyűjtését több adattárból. Sok kutató ezt a folyamatot áll iteratív böngészés több adatbázisban minden egyes gén, kézzel összejövetel gén-specifikus információt sorrend, funkció, út, illetve a betegség egyesület. Ezzel szemben DAVID szisztematikus megközelítése egyidejűleg több nyilvános adatforrásból származó biológiailag gazdag információt ad a gének listájához párhuzamosan., DAVID annotációs eszközének kiválasztása és a 402 különböző expresszált gén listájának feltöltése a teljes adatkészlet funkcionális annotációját és elemzését indítja el. A benyújtás után a génlistát a teljes elemzési munkamenetre tároljuk, lehetővé téve a felhasználók számára, hogy az adatok újbóli elküldése nélkül váltsanak a modulok között.
annotációs eszköz
az annotációs eszköz számos annotációs lehetőséget biztosít, és táblázatos képet készít a felhasználók génlistájáról és a rendelkezésre álló jegyzetekről (2.táblázat)., Kiválasztása a jegyzet mezők Gén Szimbólum, LocusLink, OMIM, Unigene, Referencia Szekvencia, valamint a Gén Neve követi, majd válassza a “Feltöltés” gombra termel egy HTML táblázat a böngésző tartalmazó gének, valamint a rendelkezésre álló kommentárok, ahol gene azonosító, leíró, valamint besorolási adatok húzta az adatbázisból, majd hozzáfűzi, hogy a gén listán (1.Ábra). Gene azonosítók, például a Gén-Szimbólum LocusLink vannak elhelyezett linkkel hivatkozott, hogy további gén-specifikus adatok nem állnak rendelkezésre az eredeti források, így biztosítva alapos gén-specifikus adatait, majd jegyzet növedékek., Az osztályozási adatok és a funkcionális összefoglalók a kutató kísérleti rendszere szempontjából releváns információk gyors beolvasására használhatók. A modul végrehajtásához szükséges szerveridő lineárisan korrelál a génlista méretével, és kevesebb, mint 45 másodpercet vesz igénybe legfeljebb 1000 gén listájához (2. ábra, a zárójelben lévő számok R2 értékeket képviselnek). Ezek az eredmények azt mutatják, hogy a nagy adatkészletek funkcionális annotációjának integrált megközelítése milyen hatékony és hatékony.,

ouput of Annotation Tool. Az ábrán látható az első több Affymetrix szonda készlethez csatolt megjegyzések egy HTML táblázatban, amely tartalmazza az összes 402 bejegyzést. A kísérleti körülményekre vonatkozó kategorikus információkat az Affymetrix szondakészlet-azonosítókkal együtt nyújtották be, amelyeket az Érték oszlopban szereplő kimenet tartalmaz. Az olyan azonosítók, mint a Symbol, LocusLink, OMIM, RefSeq és Unigene accessions, hiperhivatkozással kapcsolódnak eredetforrásukhoz a részletesebb információkért., Az összefoglaló mezőkben szereplő szöveg az NCBI LocusLink jelentésekben megadott leíró, funkcionális információkból származik.
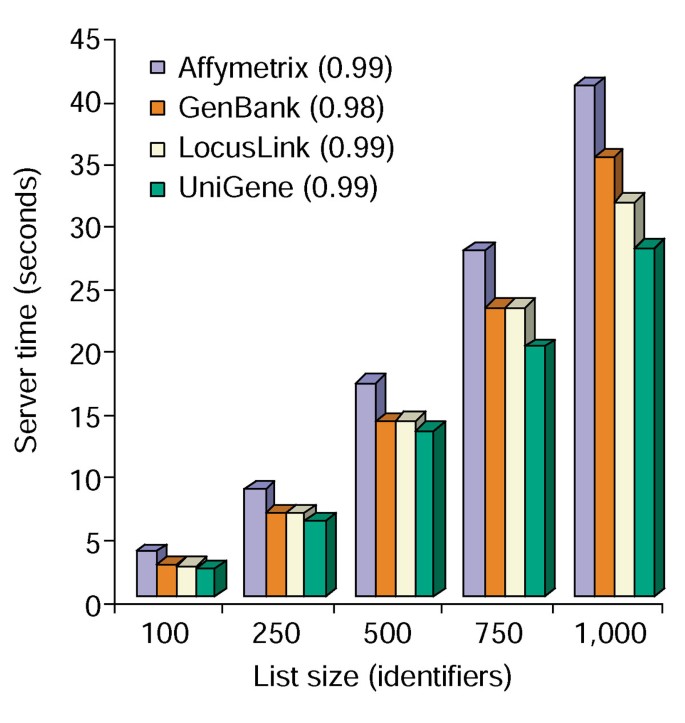
Időelemzés a megjegyzés eszköz. Szerver szükséges idő (y tengely), hogy egyszerre hozzáfűzni mind a 10 annotációs lehetőségek gén listák méretétől 100-1000 (X tengely)., Az Affymetrixet, Genbankot, Locuslinket és UniGene azonosítókat tartalmazó génlisták esetében átlagosan három vizsgálat látható, a zárójelben szereplő számok pedig a génlista mérete és az annotációhoz szükséges szerveridő közötti korreláció r2 értékét jelentik.
GoCharts
a GoCharts Modul kiválasztása új ablakot nyit meg különféle opciókkal., A felhasználók három általános osztályozási típus közül választhatnak (biológiai folyamat, molekuláris funkció és sejtkomponens), valamint öt olyan annotációs szint közül, amelyek a kifejezés lefedettségét és specifikusságát képviselik (lásd az elemzési modulok részt). A besorolás és a lefedettségi szint bármely kombinációja meghatározható. Ide tartoznak a génlisták megjegyzésének lehetőségei az összes elérhető GO kifejezéssel, vagy csak a legspecifikusabb kifejezésekkel, amelyeket terminális csomópontoknak neveznek., A különböző kifejezésspecifikus szintek kiválasztásának lehetősége biztosítja a szükséges rugalmasságot, így lehetővé teszi a kutatók számára, hogy dinamikusan meghatározzák, hogy a lefedettség és a specifitás melyik szintje felel meg legjobban adataiknak és elemzési szakaszuknak. Például a korai stádiumú elemzések a génlisták megjegyzéséből állhatnak, nagyon általános kifejezésekkel az adatok széles körű megértése érdekében. Ebben az esetben a biológiai folyamat és az 1. szint kiválasztása a géneket olyan általános kifejezésekkel osztályozza, mint a” halál “és a”sejtkommunikáció”., A megnövekedett kifejezés specifikussága megkönnyíti a részletesebb funkcionális információk kinyerését. Ebben az esetben a biológiai folyamat kiválasztása és az 5. szint a géneket olyan kifejezésekkel osztályozza, mint az” apoptotikus mitokondriális változások “és a”kemoszenzoros érzékelés”.
a megnövekedett kifejezésspecifikusság azonban költséggel jár, mivel növeli a lista lefedettségét (3. ábra). Tanulmányainkban azt találjuk, hogy a 2. szint általában jó lefedettséget tart fenn, miközben értelmes kifejezés-specifitást is biztosít., 4A ábra szemlélteti, hogy a GoCharts vizualizáció gyorsan kiderül, hogy 35 különböző expresszált gén vesz részt a “stresszválaszokban”. Minden GO kifejezés a fán vagy a DAG nézetekben megtekinthető a QuickGO hivatkozásokkal .
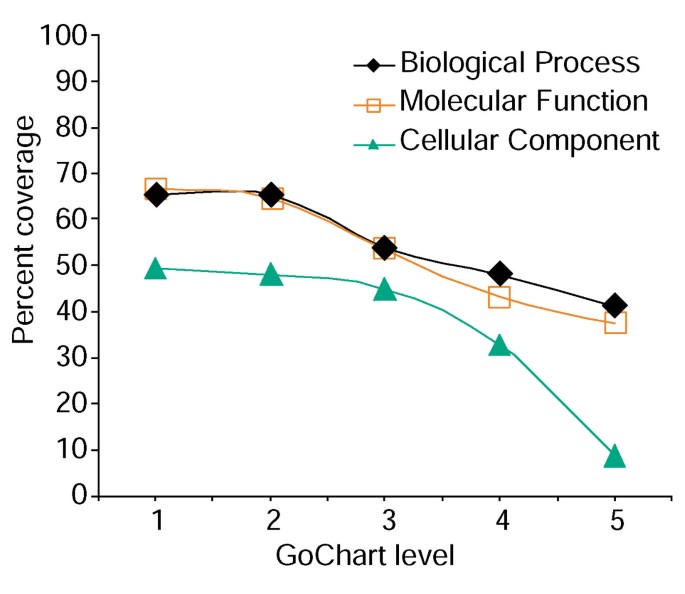
a génlista lefedettségének elemzése GoCharts segítségével. A 402 Affymetrix szonda készlet azonosítók listáját a LocusLink által biztosított Proteome hozzárendelt funkcionális osztályozásokkal jegyezték fel., Százalékos lefedettség számát jelöli gének ki 402, hogy annotált egy kifejezés, egyedi szinten belül a Biológiai Folyamat, Molekuláris Funkció, valamint a Sejtek Alkatrész osztályozási típusok. A százalékos lefedettség csökken a kifejezés specifikusságának növekedésével.
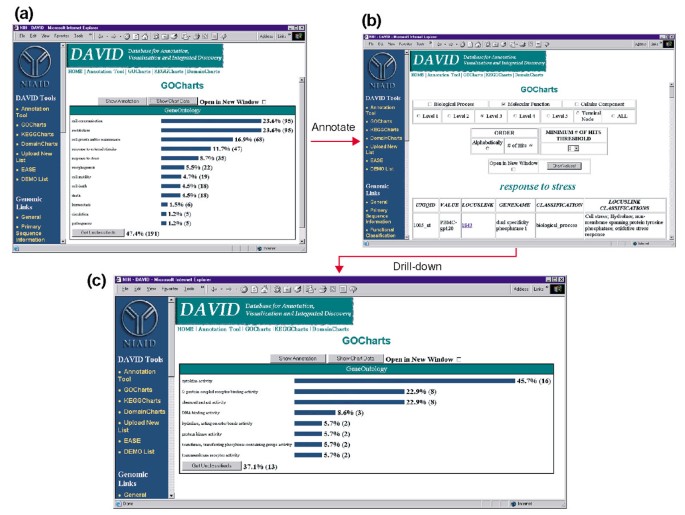
Mivel a HIV-1 nagy hatással a funkció a sejtek az immunrendszer, valamint a képesség, hogy végezzen a stressz válaszok, kiválasztottuk a hisztogram bár képviselő számú gén vesz részt a stressz reakció, ami megnyit egy HTML táblázatot, amely tartalmazza az Affymetrix azonosító, LocusLink száma, a gén neve, a jelenlegi besorolása, de más osztályozás minden 35 gének (4b Ábra)., Most, hogy csökkentettük génlistánkat azokra a génekre, amelyek részt vesznek a stresszválaszokban, tovább jellemeztük ezt az alcsoportot a stressz-válasz HTML táblázat tetején elérhető GoCharts eljárás megismétlésével. A molekuláris funkció kiválasztásával a 3. szint új hisztogramot hoz létre, amely gyorsan kiderül, hogy a stresszreakciós gének közel fele (16/35) citokin aktivitással rendelkezik (4c ábra)., Valójában kimutatták, hogy a citokinek fontos szerepet játszanak a HIV-1 életciklusában, és az itt kapott eredmények azt sugallják, hogy a Pbmc-k HIV-1 borítékfehérjékkel történő kezelése jelentősen modulálja számos citokin gén transzkripcióját. Az a hatékonyság, amellyel a GoCharts ezt a nagy adathalmazt grafikus megjelenítésekkel szisztematikusan összegezte, miközben az elsődleges adatokhoz és a külső erőforrásokhoz kapcsolódott, drasztikusan javította a felfedezési folyamatot.,
KeggCharts
5a ábra a KeggCharts kimenetét ábrázolja egy hisztogrammal, amely a differenciálisan expresszált gének eloszlását mutatja a biokémiai utak között. A diagram azt mutatja, hogy az apoptózis KEGG útja öt gént tartalmaz, amelyeket a HIV-1 gp120 indukált. Az útvonalnév kiválasztása megnyitja a megfelelő KEGG biokémiai útvonaltérképet, és piros színnel kiemeli az adott útvonalon működő differenciálisan expresszált géneket (5b ábra). Ebben a nézetben a gének tovább kapcsolódnak a KEGG”s DBGET visszakeresési rendszerén keresztül elérhető további megjegyzésekhez ., Vegye figyelembe, hogy a KEGG apoptózis útjában csak négy gén van piros színnel kiemelve, míg a KeggCharts eszköz öt Affymetrix szondát ábrázolt az apoptózis útvonalához. Ez a különbség annak a ténynek köszönhető, hogy az Affymetrix szondák közül kettő ugyanazt a “TNF-alfa” gént célozza meg.
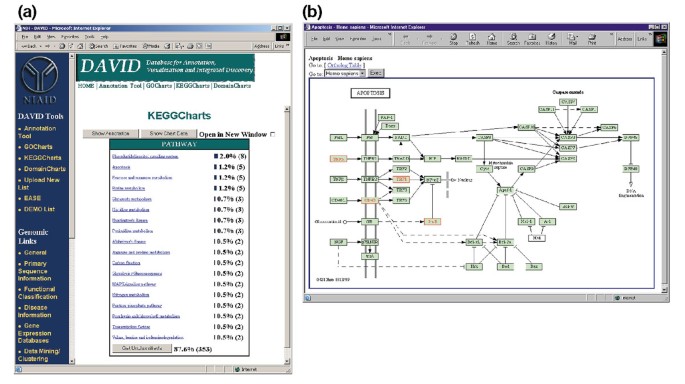
ouput of KeggCharts. (a) vizualizációs diagram, amely 402 gén eloszlását mutatja A KEGG biokémiai utak között. A találati küszöb háromra volt állítva, a kimenetet pedig találati szám szerint válogatták., A nem osztályozott azonosítók nagy száma annak köszönhető, hogy a KEGG biokémiai úton centrikus, így alacsony lefedettséget biztosít a génlisták számára. A gokartok kimenetéhez hasonlóan a kék sávok az egyes útvonalakon a gének számát képviselik. A kék sáv kiválasztásával megnyílik egy HTML táblázat, amely bemutatja az adott útvonalon lévő gének Lokuszlinkjét, génnevét, jelenlegi osztályozását és egyéb osztályozási adatait (az adatok nem jelennek meg)., (b) A KEGG biokémiai úton jelenik meg kiválasztását követően az út neve “apoptózist” az (a) ábrázolja négy differentially expresszált gének belül az apoptózis útvonal, kiemelve őket a fény, zöld, piros. Az a tény, hogy a KEGG útvonal csak négy gént emel ki, míg a KeggChart öt Affymetrix szondát térképez fel az apoptózis útvonalra, annak a ténynek köszönhető, hogy két szonda ugyanazt a “TNF-alfa” gént célozza meg.,
DomainCharts
a DomainCharts működési szempontból hasonlít mind a KeggCharts, mind a Gochartsra, kivéve, hogy az eredmények vizuálisan ábrázolják a gének eloszlását a pfam fehérje domainjei között (6a.ábra). A DomainCharts hisztogram 16 gént azonosít kináz doménekkel (pkináz), amelyek valószínűleg tükrözik a HIV-1 gp120 hatását a jelátviteli gépekre. A diagram hat gént is azonosít az interleukin-8 doménekkel (IL-8), egy olyan domén, amely a stressz-válasz citokinek között nagyon megőrzött motívumot képvisel., Az “IL8” domain név kiválasztásával megnyílik a megőrzött Domain Adatbázis (CDD) oldal, amely megfelel a PFAM domainnek (6B ábra). Ez az oldal részletes szekvenciát, struktúrát és funkcionális információt nyújt az IL-8 doménről és az azt tartalmazó fehérjékről.
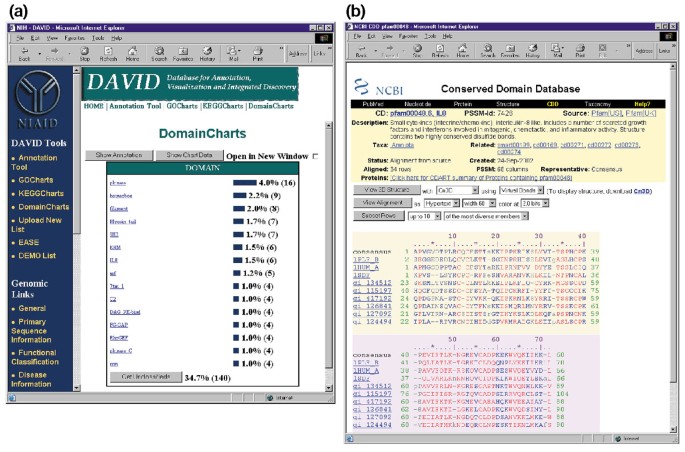
ouput of DomainCharts. (a) vizualizációs diagram, amely 402 gén eloszlását mutatja a fehérjetartományok között. A paramétereket a találati küszöbérték négyre állította, a kimenetet pedig találati szám szerint válogatta., A gokartok és a Keggchartok kimenetéhez hasonlóan a kék sávok az adott domént tartalmazó gének számát képviselik. A kék sáv kiválasztásával megnyílik egy HTML táblázat, amely bemutatja az adott útvonalon lévő gének Lokuszlinkjét, génnevét, jelenlegi osztályozását és egyéb osztályozási adatait (az adatok nem jelennek meg)., (b) a domain név megválasztása “IL8” az (a), amely tartalmazza hat differentially expresszált gének, hozza a felhasználó számára, hogy egy új oldalt, amely a kimenet a Kézirattár Domain Adatbázis (CDD) az NCBI, mely részletes információt nyújt az IL-8 domain, beleértve a strukturális információt, többszörös szekvencia-módosításokat, valamint a leíró információk a domain a fehérjék, hogy birtokolni.