Microsoft Visual Basic(VB)6で記述された自動プロシージャ。,0匿名ファイル転送プロトコル(FTP)を介して公開データをダウンロードする一連のPerlおよびJavaアプリケーションを呼び出す(表1)、目的の注釈データを解凍して解 MicrosoftのIIE webサーバーとActive Server Pageテクノロジは、JavaBeansと構造化クエリ言語(SQL)を使用してデータベースにアクセスするために使用されます。, AffymetrixプローブセットのLocusLink番号は、ミシガン大学協会またはNetAffxから導出されます。 機能的な注釈とデータベースの相互参照は、遺伝子の安定した、ヒトキュレーションされた表現を提供するLocusLinkから派生しています。 DAVIDが使用しているデータソースの詳細については、FAQのセクションを参照してください。,
解析モジュール
DAVIDは、注釈ツール、GoCharts、KeggCharts、DomainChartsの四つの主要なモジュールで構成されています。 アノテーションツールは、遺伝子リストの機能的注釈のための自動化された方法です。 組み合わせのアノテーションデータから選択することができ10オプションを選択し、適切なチェックボックス(表2)。, アップロードボタンを選択すると、選択した機能アノテーションが付加されたユーザーの元の識別子リストを含むHTMLテーブルが返されます。 ノーテーションされていない遺伝子は、追跡目的で追加されたデータなしで出力に含まれます。,
Gchartsモジュールは、遺伝子オントロジーコンソーシアム(GO)の制御された語彙を使用して、機能カテゴリ間の差発現遺伝子の分布をグラフィカルに表示します。蓄積して変化する。, 言語は有向非巡回グラフ(DAG)で構成されており、階層が下に移動するにつれて用語特異性が増加し、ゲノムカバレッジが減少する。 真の階層とは対照的に、DAG内の子用語は複数の親用語を持ち、その親とは異なるクラスの関係を持つことがあります。 GOの構造は、生物学的プロセス、分子機能、および細胞成分の三つの主要なカテゴリーから始まります。, 生物学的プロセスには、分子機能の秩序付けられた集合によって達成される有糸分裂またはプリン代謝などの広範な生物学的目標が含まれる。 分子機能は、個々の遺伝子産物によって実行されるタスクを記述し、例は、転写因子およびDNAヘリカーゼである。 細胞成分分類タイプには、細胞内構造、位置、および高分子複合体が含まれ、例としては、核、テロメア、および起源の認識複合体が含まれる。, 分類タイプを選択した後、適切なラジオボタンを選択して、リストの適用範囲と特異性を決定するレベルが選択されます。 レベル1は、用語特異性の最小量で最高のリストカバレッジを提供します。 各レッスンまでの範囲の減少が特異性の増加でレベル5の少なくとも金額保険の最期特異性が挙げられる。
分類データは棒グラフとして表示され、棒の長さは各カテゴリの遺伝子識別子の数を表します。, ユーザー設定可視化パラメータをソートに出力データの表示システムを作ることが含まれるようにしてください少なくとも最低限の数の遺伝子です。 個々のバーを選択すると、遺伝子識別子、遺伝子座リンク番号、遺伝子名、現在の分類、およびそのカテゴリ内の各遺伝子のその他の分類を表示する新しいHTMLテーブルが開きます。 “すべて表示”ボタンは、すべての分類データを表示する新しいHTMLテーブルを開き、”グラフデータを表示”ボタンは、基になるグラフデータを含むHTMLテーブルを開きます。, 新しいグラフは、ドリルダウン機能を可能にするユーザーの現在のページ内で利用可能なチェックボックスとラジオボタンを使用して分類タイプとレベ 注釈された遺伝子の数のカウントが出力に含まれ、注釈されていない遺伝子は”未分類”カテゴリにビンニングされ、注釈されていない遺伝子の自動追跡システムがユーザーに提供されます。
KeggChartsは、kegg生化学経路間の差発現遺伝子の分布をグラフィカルに表示します。, 各経路はKEGG経路マップにリンクされており、元のリストからの差次的に発現された遺伝子は赤色で強調表示されている。 この見解では、遺伝子はKEGGのDBGET検索システムを通じて利用可能な追加の注釈にさらにリンクされています。 Gchartsと同様に、ユーザーは出力データをソートし、少なくとも最小数の遺伝子を含むカテゴリを表示するための視覚化パラメータを設定でき、keggchartsの視覚化はGchartsのすべての動的機能を継承します。
ドメインチャートは、PFAMタンパク質ドメイン間で差次的に発現された遺伝子の分布を表示します。, 各ドメイン指定は、国立バイオテクノロジー情報センター(NCBI)の保存されたドメインデータベース(CDD)にリンクされており、ドメイン機能、構造および配列に関する詳細 GchartsおよびKeggChartsと同様に、ユーザーは出力データをソートし、少なくとも最小数の遺伝子を含むカテゴリを表示するための視覚化パラメータを設定でき、DomainChartsの視覚化はGchartsおよびKeggChartsのすべての動的機能を継承します。 DAVIDの機能に関する詳細については、FAQセクションをご覧ください。,
DAVIDを使用して機能アノテーションを採掘する
DAVIDの機能を実証するために、HIV-1エンベロープタンパク質とのインキュベーション後、ヒト末梢血単核細胞(PBMCs) 実験的手順、RNA調製、およびGenechipハイブリダイゼーション手順の詳細、ならびにchip-to-chip正規化および差動遺伝子発現の統計的解析の詳細は、Cicala et al. ., 簡単に言えば、プライマリヒトPBMCsと単球由来マクロファージは16時間HIV-1エンベロープタンパク質(gp120)でインキュベートしました。 高密度オリゴヌクレオチドマイクロアレイ(Affymetrix HU-95A GeneChip)は、gp120誘導転写イベントを監視するために使用されました。 この分析は、402差発現遺伝子の同定をもたらした。
HIV-16gp120によって変調された遺伝子は、以前にHIV複製および/またはエンベロープシグナル伝達に関連付けられているのに対し、残りの遺伝子は未知の機, 変換するこのリストの遺伝子の生物学的意味の収集の情報から複数のデータリポジトリ 多くの研究者にとって、このプロセスは、各遺伝子のいくつかのデータベースを反復的に閲覧し、配列、機能、経路、および疾患関連に関する遺伝子特異的情報 対照的に、DAVIDの体系的なアプローチは、いくつかの公開データソースから得られた生物学的に豊富な情報を並行して遺伝子のリストに同時に追加する。, DAVIDのアノテーションツールを選択し、402の差別発現遺伝子のリストをアップロードすると、データセット全体の機能的なアノテーションと分析が開始さ 送信されると、遺伝子リストは分析セッション全体に保存され、ユーザーはデータを再送信することなくモジュールを切り替えることができます。
注釈ツール
注釈ツールは、いくつかの注釈オプションを提供し、ユーザー遺伝子リストと利用可能な注釈の表形式ビューを構築します表2。, アノテーションフィールドGene Symbol、LocusLink、OMIM、Unigene、Reference Sequence、Gene Nameを選択した後、”アップロード”ボタンを選択すると、すべての遺伝子と利用可能なアノテーションを含むHTMLテーブルがwebブラウザに表示され、遺伝子識別子、記述データ、分類データがデータベースから取得され、遺伝子リストに追加されます(図1)。 Gene SymbolやLocusLinkなどの遺伝子識別子は、元のソースで利用可能な追加の遺伝子特-なデータにハイパーリンクされているため、詳細な遺伝子特specificな詳細と注, 分類データと機能概要は、研究者の実験システムに関連する情報を迅速にスキャンするために使用することができます。 このモジュールの実行に必要なサーバー時間は、遺伝子リストのサイズと線形に相関し、45秒以内に最大1,000個の遺伝子のリストが作成されます(図2、カッコ内の数字はr2の値を表します)。 これらの結果は、電力効率の統合的アプローチの機能アノテーションの大規模なデータセット.,

注釈ツールの出力。 すべての402のエントリを含むHTMLテーブル内の最初のいくつかのAffymetrixプローブセットの注釈が追加されています。 実験条件に関するカテゴリ情報がAffymetrixプローブセット識別子とともに提出され、value列の出力に含まれました。 Symbol、LocusLink、OMIM、RefSeq、およびUnigeneアクセッションなどの識別子は、より詳細な情報を得るために、それらの起源ソースにハイパーリンクされています。, 要約フィールドに含まれるテキストは、NCBIのLocusLinkレポートで提供される説明的な機能情報から派生します。
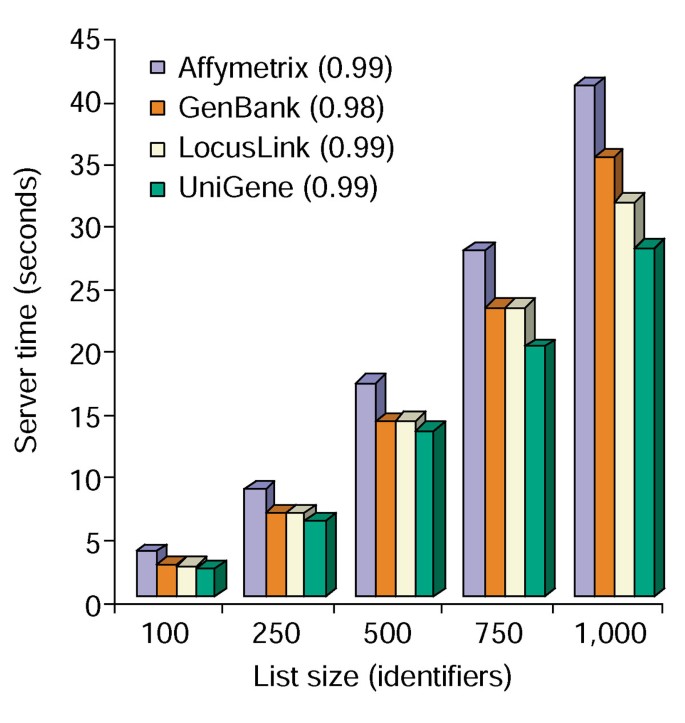
注釈ツールの時間分析。 10個のアノテーションオプションをすべて同時に遺伝子リストに追加するのに必要なサーバー時間(y軸)100から1,000(x軸)のサイズの範囲です。, Affymetrix、GenBank、LocusLink、およびUniGene識別子を含む遺伝子リストの三つの試験の平均が示されており、括弧内の数字は、遺伝子リストのサイズと注釈に必要なサーバー時間との間の相関のr2値を表している。
GoCharts
GoChartsモジュールを選択すると、さまざまなオプションを持つ新しいウィンドウが開きます。, ユーザーは、分類の三つの一般的なタイプ(生物学的プロセス、分子機能、および細胞成分)と用語のカバレッジと特異性を表す注釈の五つのレベル(分析モジュールのセクションを参照)の間で選択する。 分類とカバレッジレベルの任意の組み合わせを指定できます。 また、利用可能なすべてのGO用語または端末ノードと呼ばれる最も具体的な用語のみで遺伝子リストに注釈を付けるオプションも含まれています。, 用語特異性の異なるレベルを選択するオプションは、必要な柔軟性を提供し、したがって、研究者は、カバレッジと特異性の最高の彼らのデータと分析 例えば、初期段階の分析は、データの広範な理解を得るために、非常に一般的な用語で遺伝子リストに注釈を付けることからなり得る。 この場合、生物学的プロセスとレベル1を選択すると、”死”や”細胞コミュニケーション”などの一般的な用語を使用して遺伝子を分類します。, 増加した用語特異性を使用すると、より詳細な機能情報の抽出が容易になります。 この場合、生物学的プロセスとレベル5を選択すると、”アポトーシスミトコンドリアの変化”や”化学感覚知覚”などの用語を使用して遺伝子を分類します。
しかし、用語特異性の増加は、リストのカバレッジが増加するにつれて減少するという点で、コストがかかります(図3)。 我々の研究その2一般的に良好険を提供する有意義な期特異性が挙げられる。, 図4aは、Gchartsの可視化により、35個の異なって発現された遺伝子が”ストレス応答”に関与していることを迅速に示しています。 各GO用語は、QuickGOへのハイパーリンクによってツリービューまたはDAGビューで表示できます。
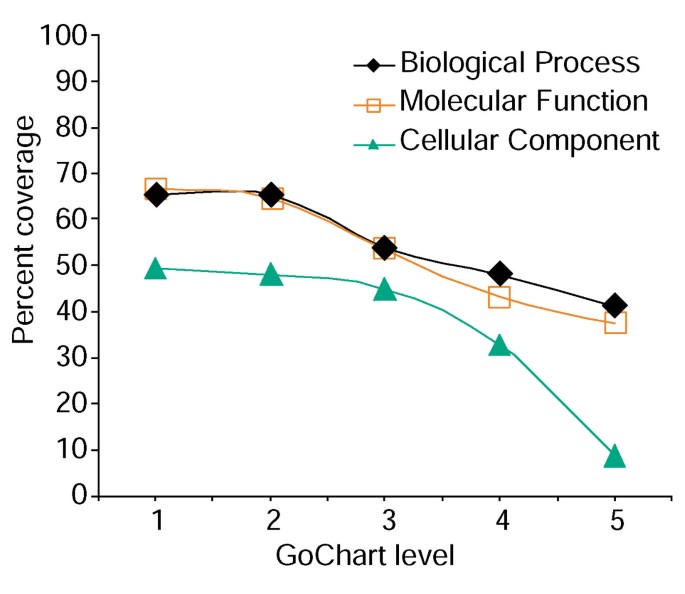
Gchartsを使用した遺伝子リストカバレッジの解析。 402Affymetrixプローブセット識別子のリストは、LocusLinkによって提供されるプロテオーム割り当てられた機能分類で注釈が付けられました。, パーセントカバレッジは、生物学的プロセス、分子機能、および細胞成分の分類タイプ内の用語特異性レベルで注釈された402のうちの遺伝子の数を表 %の範囲が減少していくこと、期特異性が増加します。
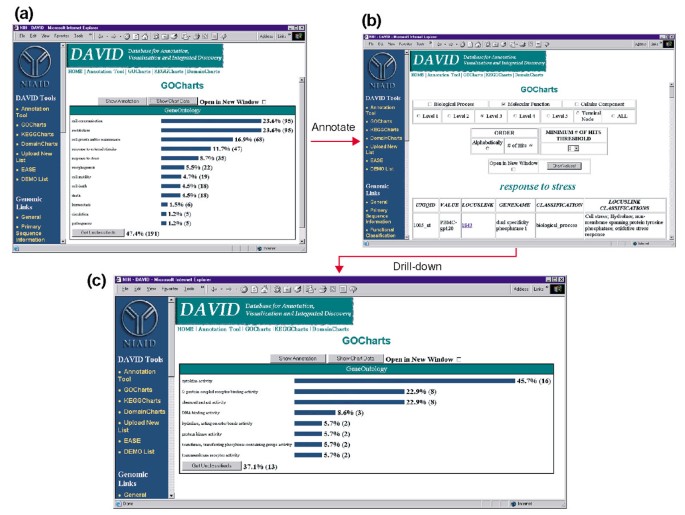
Gchartsの出力。 (a)遺伝子オントロジー(GO)生物学的プロセス間で差次的に発現された遺伝子の分布を示す棒グラフ。, パラメータはGOレベル2に設定され、ヒットしきい値は五つに設定され、出力はヒット数でソートされました。 青いバーは、(b)に示す追加の注釈データにリンクされています。 “ストレスへの応答”に対応する(a)の青いバーを選択すると、そのカテゴリー内の遺伝子のLocusLink、遺伝子名、現在の分類、およびその他の分類データを示すHTMLテーブル (c)”ストレス応答”に関与する遺伝子のこのサブセットは、GO分子機能、GOレベル3、2のヒット閾値を選択し、ヒットカウントによってソートすることによ, を選択する”図表値”ボタンをヒストグラムを解明する16の35ストレス応答遺伝子のエンコードタンパク質を有サイトカインです。,
HIV-1は免疫系の細胞の機能とストレス応答を行う能力に大きな影響を与えるため、ストレス応答に関与する遺伝子の数を表すヒストグラムバーを選択し、35個の遺伝子すべてについてAffymetrix識別子、遺伝子座リンク数、遺伝子名、現在の分類、およびその他の分類を含むHTMLテーブルを開く(図4b)。, ストレス応答に関与する遺伝子に遺伝子リストを減らしたので、ストレス応答HTMLテーブルの上部にあるGoCharts手順を繰り返すことによって、このサブセットをさらに特徴付けました。 分子機能を選択すると、レベル3は、ストレス応答遺伝子のほぼ半分(16/35)がサイトカイン活性を有することをすぐに明らかにする新しいヒストグラムを生成する(図4c)。, 確かに、サイトカインは、HIV-1のライフサイクルで重要な役割を果たすことが示されており、ここで得られた結果は、HIV-1エンベロープタンパク質とPBMCsの治療が大幅に多数のサイトカイン遺伝子の転写を調節することを示唆している。 GoChartsがこの大規模なデータセットをグラフィックビジュアライゼーションで体系的に要約し、プライマリデータや外部リソースにリンクしたままであること,
KeggCharts
図5aは、生化学経路間の差発現遺伝子の分布を表示するヒストグラムとKeggChartsの出力を示しています。 このアプローチは、KEGG pathwayのアポトーシストの遺伝子によるHIV-1のgp120. 経路名を選択すると、対応するKEGG生化学経路マップが開き、赤でハイライトされ、その経路で機能する差次的に発現された遺伝子の輪郭が描かれます(図5b)。 この見解では、遺伝子はKEGGのDBGET検索システムを通じて利用可能な追加の注釈にさらにリンクされています。, KeggChartsツールは、アポトーシス経路に五Affymetrixプローブセットをマッピングしながら、KEGG apoptosis経路の唯一の四つの遺伝子が赤で強調表示されていることに注意してください。 この違いは、Affymetrixプローブセットの二つが同じ”TNF-α”遺伝子を標的としているという事実によるものです。
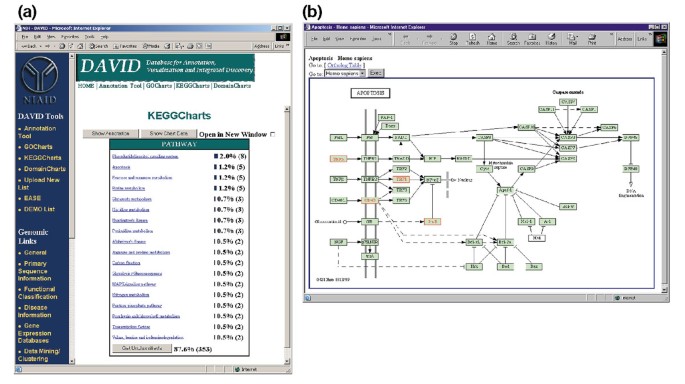
KeggChartsの出力。 (a)KEGG生化学経路間の402遺伝子の分布を示す可視化チャート。 ヒットしきい値を三つに設定し、出力をヒットカウントでソートしました。, 多数の未分類識別子は、KEGGが生化学経路中心であり、したがって遺伝子リストのカバレッジが低いという事実によるものである。 Gchartsの出力と同様に、青いバーは各経路の遺伝子の数を表します。 青いバーを選択すると、その経路における遺伝子のLocusLink、遺伝子名、現在の分類、およびその他の分類データ(データは示されていない)を示すHTMLテーブルが開きます。, (b)(a)における経路名”アポトーシス”の選択に続いて現れるKEGG生化学的経路は、アポトーシス経路内の四つの異なって発現された遺伝子を薄緑および赤でハイライトすることによって描いている。 KEGG経路は四つの遺伝子のみをハイライトするのに対し、KeggChartは五つのAffymetrixプローブセットをアポトーシス経路にマップするという事実は、二つのプローブセットが同じ”TNF-α”遺伝子を標的とするという事実によるものである。,
ドメインチャート
ドメインチャートは、PFAMタンパク質ドメイン間の遺伝子の分布を視覚的に示す結果を除いて、keggchartsとGoChartsの両方に動作的に似ています図6a。 DomainChartsヒストグラムは、おそらくシグナル伝達機構に対するHIV-16gp120の影響を反映して、キナーゼドメイン(pkinase)を持つ遺伝子を識別します。 チャートはまた、インターロイキン-8ドメイン(IL-8)、ストレス応答サイトカインの間で高度に保存されたモチーフを表すドメインを持つ六つの遺伝子を識別, ドメイン名”IL8″を選択すると、そのPFAMドメインに対応する保存されたドメイン-データベース(CDD)ページが開きます(図6b)。 このページでは、IL-8ドメインとそれを含むタンパク質に関する詳細な配列、構造、および機能情報を提供します。
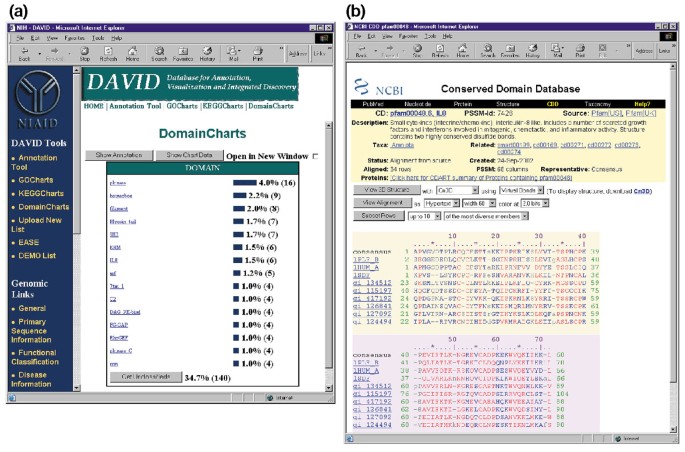
ドメインチャートの出力。 (a)タンパク質ドメイン間の402遺伝子の分布を示す可視化チャート。 パラメータは最小ヒットしきい値に設定され、出力はヒットカウントでソートされました。, GoChartsおよびKeggChartsの出力と同様に、青いバーはその特定のドメインを含む遺伝子の数を表します。 青いバーを選択すると、その経路における遺伝子のLocusLink、遺伝子名、現在の分類、およびその他の分類データ(データは示されていない)を示すHTMLテーブルが開きます。, (b)(a)のドメイン名”IL8″を選択すると、NCBIの保存されたドメインデータベース(CDD)からの出力を含む新しいページに移動し、IL-8ドメインに関する詳細な情報、構造情報、複数の配列アライメント、ドメインおよびそれを持つタンパク質に関する記述情報を提供する。