ett automatiserat förfarande skrivet i Microsoft Visual Basic (VB) 6.,0 uppdaterar DAVID weekly med följande procedurer: ring en serie Perl-och Java-program som laddar ner offentliga data via anonyma filöverföringsprotokoll (FTP) (Tabell 1); Packa upp och analysera önskade annoteringsdata; skapa tabbavgränsade datafiler redo för databasimport; och importera data till ett Oracle 8i relational database management system (RDBMS) med Oracle”s SQL*Loader application. Microsofts IIE web server-och Active Server Page-teknik används för att komma åt databasen med JavaBeans och SQL (structured query language)., LocusLink nummer för Affymetrix sond sätter härrör från University of Michigan föreningar eller NetAffx . Funktionella anteckningar och databas korsreferenser härrör från LocusLink, som ger stabila, human-curated representationer av gener. För mer detaljerad information om de datakällor som används av DAVID, se FAQ-avsnittet på .,
analysmoduler
DAVID består av fyra huvudmoduler: Annoteringsverktyg, GoCharts, KeggCharts och DomainCharts. Annoteringsverktyget är en automatiserad metod för funktionell anteckning av genlistor. Varje kombination av annoteringsdata kan väljas från 10 alternativ genom att välja lämpliga kryssrutor (Tabell 2)., Anteckningarna läggs till i den inlämnade genlistan genom att välja knappen Ladda upp, som returnerar en HTML-tabell som innehåller användarens ursprungliga lista över identifierare bifogade med de valda funktionella anmärkningarna. Oannoterade gener ingår i produktionen utan bifogade data för spårning.,
Gochartsmodulen visar grafiskt fördelningen av differentiellt uttryckta gener bland funktionella kategorier med hjälp av det kontrollerade ordförrådet i Genet Ontologikonsortium (GO), vilket ger ett strukturerat språk som kan tillämpas på funktionerna hos gener och proteiner i alla organismer, även som en kunskap fortsätter att ackumuleras och förändras ., Språket är strukturerat i ett riktat acykliskt diagram (DAG), där termen specificitet ökar och genomtäckningen minskar när man rör sig ner i hierarkin. I motsats till en sann hierarki kan underordnade termer i en DAG ha mer än en överordnad term och kan ha en annan klass av relation med sina olika föräldrar. Strukturen av GO börjar med tre huvudkategorier, biologisk Process, Molekylär funktion och cellulär komponent., Biologisk Process innefattar breda biologiska mål, såsom mitos eller purinmetabolism, som uppnås genom beställda sammansättningar av molekylära funktioner. Molekylär funktion beskriver de uppgifter som utförs av enskilda genprodukter; exempel är transkriptionsfaktor och DNA helicase. Cellkomponentklassificeringstypen innefattar subcellulära strukturer, platser och makromolekylära komplex; exempel inkluderar nucleus, telomere och origin recognition complex., Efter att ha valt en klassificeringstyp väljs nivåer som bestämmer listtäckning och specificitet genom att välja lämplig radioknapp. Nivå 1 ger den högsta listtäckningen med minst sikt specificitet. Med varje ökande nivå minskar täckningen medan specificiteten ökar så att Nivå 5 ger minst täckning med högsta sikt specificitet.
Klassificeringsdata visas som ett stapeldiagram, där längden på stapeln representerar antalet genidentifierare i varje kategori., Användaren kan ställa in visualiseringsparametrar för sortering av utdata och visning av kategorier som innehåller minst ett minimalt antal gener. Genom att välja en enskild stapel öppnas en ny HTML-tabell som visar genidentifieraren, LocusLink-numret, gennamnet, den aktuella klassificeringen och andra klassificeringar för varje gen i den kategorin. En” Visa alla ”- knapp Öppnar en ny HTML-tabell som visar alla klassificeringsdata och en” Visa diagramdata ” – knapp Öppnar en HTML-tabell som innehåller de underliggande diagramdata, vilket gör det möjligt för användare att återskapa anpassade diagramgrafik i ett kalkylprogram., Ett nytt diagram kan visas för någon delmängd av gener genom att välja klassificeringstyp och nivå med hjälp av kryssrutorna och radioknapparna tillgängliga inom användarens aktuella sida som möjliggör borrning kapacitet. En räkning av antalet annoterade gener ingår i produktionen, och oannoterade gener binds in i kategorin” oklassificerade”, vilket ger användarna ett automatiserat spårningssystem för gener som inte kommenteras.
keggcharts visar grafiskt fördelningen av differentiellt uttryckta gener bland Kegg biokemiska vägar., Varje väg är kopplad till Kegg pathway kartan, varvid differentiellt uttryckta gener från den ursprungliga listan markeras i rött. I denna vy är gener ytterligare kopplade till ytterligare anteckningar tillgängliga via KEGG”s DBGET retrieval system . Som med GoCharts kan användaren ställa in visualiseringsparametrar för sortering av utdata och visning av kategorier som innehåller minst ett minimalt antal gener och keggcharts visualisering ärver alla dynamiska funktioner i GoCharts.
DomainCharts visar fördelningen av differentiellt uttryckta gener bland PFAM-proteindomäner ., Varje domänbeteckning är kopplad till den konserverade Domändatabasen (CDD) för National Center for Biotechnology Information (NCBI), där information om domänfunktion, struktur och sekvens är lättillgängliga. Som med GoCharts och KeggCharts, kan användaren ställa in visualisering parametrar för sortering, utdata och visning av kategorier som innehåller minst ett minsta antal gener och DomainCharts visualisering ärver alla de dynamiska funktioner av GoCharts och KeggCharts. För ytterligare information om Davids funktionalitet besök FAQ-sektionen på .,
använda DAVID för att bryta funktionell anteckning
för att visa Davids funktionalitet analyserade vi en lista över gener som differentiellt uttrycks i humana perifera blodmononukleära celler (Pbmc) efter inkubation med HIV-1 kuvertproteiner. Detaljer om experimentella, rna-preparat och GeneChip hybridiseringsprocedurer, tillsammans med detaljer om chip-to-chip normaliseringar och statistisk analys av differentialgenuttryck tillhandahålls i Cicala et al. ., I korthet inkuberades primära humana Pbmc och monocyt-härledda makrofager i 16 timmar med HIV-1 kuvertprotein (gp120). Högdensitetsoligonukleotidmikroarrays (Affymetrix HU-95A GeneChip) användes för att övervaka gp120-inducerade transkriptionella händelser. Denna analys resulterade i identifieringen av 402 differentiellt uttryckta gener.
medan 16 gener som moduleras av HIV-1 gp120 tidigare har associerats med HIV-replikation och/eller kuvertsignalering, är de återstående generna av okänd funktion eller har aldrig associerats med HIV-1 eller gp120., Att omvandla denna lista över gener till biologisk betydelse kräver insamling av relevant information från flera dataförråd. För många forskare består denna process av iterativ surfning genom flera databaser för varje gen, som manuellt samlar genspecifik information om sekvens, funktion, väg och sjukdomsförening. Däremot lägger DAVID systematiskt tillvägagångssätt samtidigt biologiskt rik information som härrör från flera offentliga datakällor till listor över gener parallellt., Välja DAVID ” s anteckning verktyg och ladda upp listan över 402 differentiellt uttryckta gener initierar funktionell anteckning och analys av hela datauppsättningen. När genen har lämnats in lagras listan för hela analyssessionen, så att användarna kan växla mellan moduler utan att behöva skicka in data igen.
Annoteringsverktyg
Annoteringsverktyget ger flera annoteringsalternativ och bygger en tabellvy av användargenlistan och de tillgängliga annoteringarna (Tabell 2)., Att välja annoteringsfälten Gensymbol, LocusLink, OMIM, Unigene, Referenssekvens och Gennamn följt av att välja ”Ladda upp” – knappen ger en HTML-tabell i webbläsaren som innehåller alla gener och deras tillgängliga anteckningar, där genidentifierare, beskrivande och klassificeringsdata dras från databasen och bifogas genlistan (Figur 1). Genidentifierare som Gensymbol och LocusLink är hyperlänkade till ytterligare genspecifika data som finns tillgängliga på deras ursprungliga källor, vilket ger djupgående genspecifika detaljer och annoteringsstadier., Klassificeringsdata och funktionella sammanfattningar kan användas för att snabbt söka efter information som är relevant för forskarens experimentella system. Den servertid som krävs för utförandet av denna modul korrelerar linjärt med genlistans storlek och tar mindre än 45 sekunder för listor med upp till 1000 gener (Figur 2, siffror inom parentes representerar R2-värden). Dessa resultat visar kraften och effektiviteten i ett integrerat tillvägagångssätt för funktionell anteckning av stora datauppsättningar.,

Ouput av Annoteringsverktyg. Visas bifogas anteckningar för de första flera Affymetrix probe uppsättningar i en HTML-tabell som innehåller alla 402 poster. Kategorisk information om experimentella förhållanden lämnades tillsammans med Affymetrix probe-set identifierare och ingår i produktionen i kolumnen värde. Identifierare som Symbol, LocusLink, OMIM, RefSeq och Unigene-anslutningar är hyperlänkade till deras ursprungskällor för mer detaljerad information., Text som ingår i sammanfattningsfält härrör från beskrivande, funktionell information som tillhandahålls i NCBI”s LocusLink rapporter.
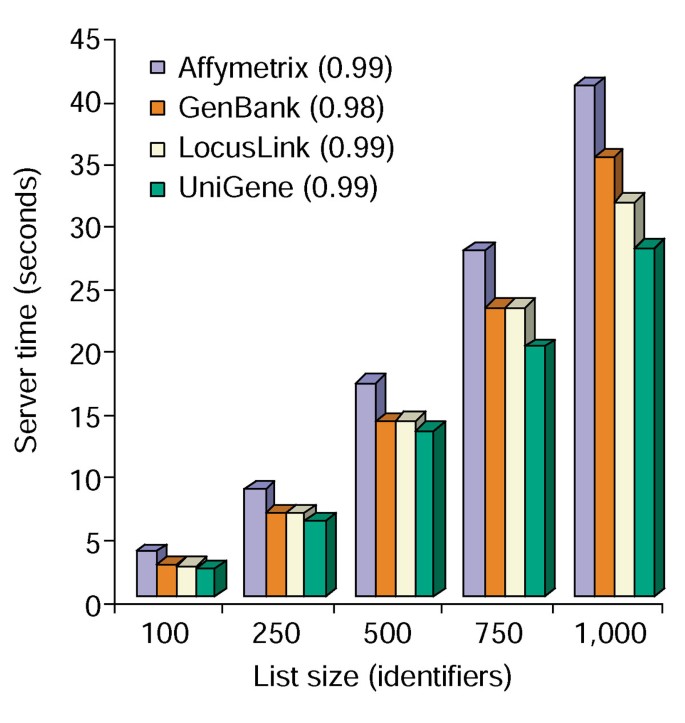
tidsanalys av Annoteringsverktyg. Server tid som krävs (Y axel) för att samtidigt lägga alla 10 annotation alternativ till genlistor varierar i storlek från 100 till 1000 (x axel)., I genomsnitt visas tre försök för genlistor som innehåller Affymetrix, GenBank, LocusLink och UniGene-identifierare och siffrorna inom parentes representerar R2-värdet av korrelationen mellan genlistansstorlek och den servertid som krävs för anteckning.
GoCharts
genom att välja gocharts-modulen öppnas ett nytt fönster med olika alternativ., Användare väljer mellan tre allmänna typer av klassificering (biologisk process, molekylär funktion och cellulär komponent) och fem nivåer av anteckning som representerar termen täckning och specificitet (se avsnittet analysmoduler). Varje kombination av klassificering och täckningsnivå kan specificeras. Dessutom ingår alternativ för att kommentera genlistor med alla Go termer tillgängliga eller bara de mest specifika termer, som kallas terminal noder., Möjligheten att välja olika nivåer av termen specificitet ger nödvändig flexibilitet och gör det möjligt för forskare att dynamiskt bestämma vilken nivå av täckning och specificitet som bäst passar deras data och analysstadium. Till exempel kan tidiga analyser bestå av att kommentera genlistor med mycket allmänna termer för att få en bred förståelse av data. I detta fall klassificerar val av biologisk process och nivå 1 gener med allmänna termer som” död ”och”cellkommunikation”., Med hjälp av ökad term specificitet underlättar utvinning av mer detaljerad funktionell information. I detta fall klassificerar val av biologisk process och nivå 5 gener med termer som ”apoptotiska mitokondriella förändringar”och” kemosensorisk uppfattning”.
ökad term specificitet kommer dock en kostnad, eftersom det ökar listtäckningen minskar (Figur 3). I våra studier finner vi att Nivå 2 normalt upprätthåller god täckning samtidigt som det ger meningsfull term specificitet., Figur 4a illustrerar hur visualiseringen av GoCharts snabbt visar att 35 differentiellt uttryckta gener är involverade i”stressrespons”. Varje GO sikt kan ses i trädet eller DAG vyer av hyperlänkar till QuickGO .
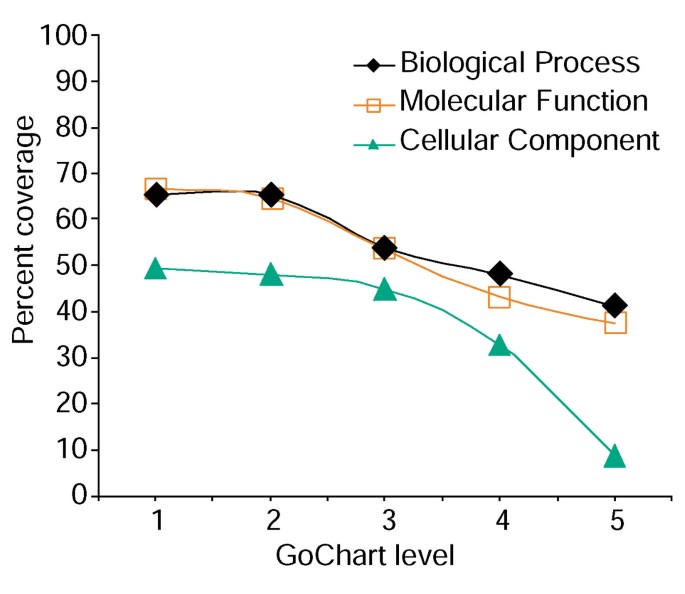
analys av genlistans täckning med hjälp av GoCharts. En lista över 402 Affymetrix probe set identifierare kommenterades med Proteome tilldelade funktionella klassificeringar som tillhandahålls av LocusLink., Procent täckning representerar antalet gener av 402 som kommenterades på en term-specificitet nivå inom den biologiska processen, Molekylär funktion, och cellulära Komponentklassificeringstyper. Procentuell täckning minskar när termen specificitet ökar.
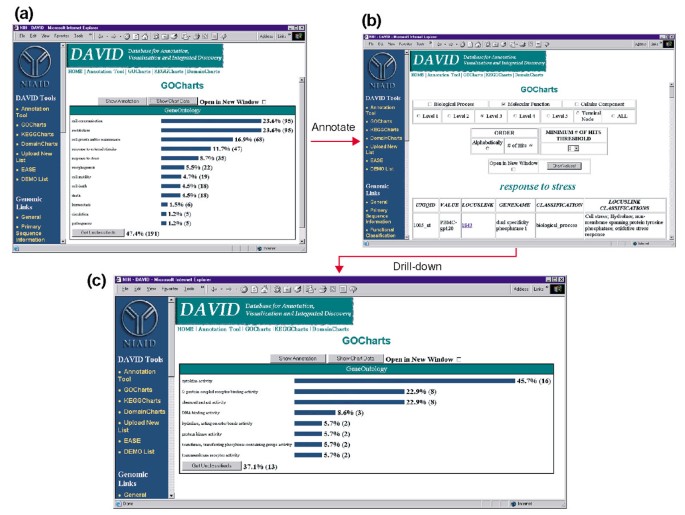
Ouput av GoCharts. (A) ett stapeldiagram som visar fördelningen av differentiellt uttryckta gener bland Gen ontologi (GO) biologiska processer., Parametrar sattes till go nivå 2, en träff tröskel på fem, och produktionen sorterades efter träff räkna. Blå staplar är kopplade till ytterligare annoteringsdata som visas i b. Om du väljer den blå stapeln i (A) som motsvarar ”respons på stress” öppnas en HTML-tabell som visar LocusLink, gennamn, aktuell klassificering och andra klassificeringsdata för generna i den kategorin. (C) denna delmängd av gener som är involverade i ”stressrespons” karakteriserades ytterligare genom att välja Go Molekylär funktion, GO nivå 3, en träfftröskel på 2 och sorteras efter träffantal., Genom att välja knappen” Diagramvärden ” skapas ett nytt histogram som visar att 16 av de 35 stressresponsgenerna kodar för proteiner som har cytokinaktivitet.,
eftersom HIV-1 har en stor inverkan på immunsystemets funktion och deras förmåga att utföra stressreaktioner, valde vi histogramfältet som representerar antalet gener som är involverade i stressrespons, vilket öppnar en HTML-tabell som innehåller Affymetrix-identifieraren, LocusLink-nummer, gennamn, nuvarande klassificering och andra klassificeringar för alla 35 gener (figur 4b)., Nu när vi har minskat vår genlista till de gener som är involverade i stressrespons, karakteriserade vi vidare denna delmängd genom att upprepa GoCharts-proceduren som finns överst i stress-response HTML-tabellen. Genom att välja molekylär funktion producerar nivå 3 ett nytt histogram som snabbt avslöjar att nästan hälften (16/35) av stressresponsgenerna har cytokinaktivitet (figur 4c)., Cytokiner har faktiskt visat sig spela en viktig roll i HIV – 1-livscykeln och de resultat som erhållits här tyder på att behandling av Pbmc med HIV-1-kuvertproteiner väsentligt modulerar transkriptionen av många cytokingener. Effektiviteten med vilken GoCharts systematiskt sammanfattade denna stora datauppsättning med grafiska visualiseringar, samtidigt som den var kopplad till primära data och externa resurser avsevärt förbättrade upptäcktsprocessen.,
KeggCharts
figur 5a visar produktionen av KeggCharts med ett histogram som visar fördelningen av differentiellt uttryckta gener bland biokemiska vägar. Diagrammet visar att en Kegg-väg för apoptos innehåller fem gener inducerade av HIV-1 gp120. Att välja pathway namn öppnar motsvarande Kegg biokemisk pathway karta och belyser i rött skissera differentiellt uttryckta gener fungerar i den vägen (figur 5b). I denna vy är gener ytterligare kopplade till ytterligare anteckningar tillgängliga via KEGG”s DBGET retrieval system ., Observera att endast fyra gener i Kegg apoptosvägen är markerade i rött, medan KeggCharts-verktyget mappade fem Affymetrix-sonden sätter till apoptosvägen. Denna skillnad beror på det faktum att två av Affymetrix-sonderna riktar sig mot samma ”TNF-alfa” – gen.
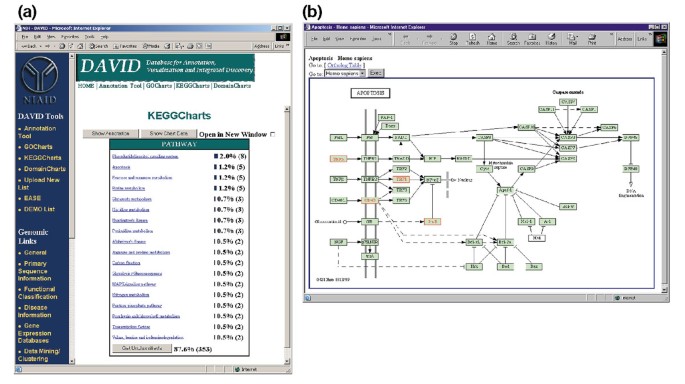
Ouput av KeggCharts. (a) Visualiseringsdiagram som visar fördelningen av 402 gener bland Kegg biokemiska vägar. Träfftröskeln var inställd på tre och utgången sorterades efter träffantal., Det stora antalet oklassificerade identifierare beror på det faktum att KEGG är biokemisk väg centrerad och därmed ger låg täckning av genlistor. På samma sätt som produktionen av GoCharts representerar blåstänger antalet gener i varje väg. Om du väljer en blå stapel öppnas en HTML-tabell som visar LocusLink, gennamn, aktuell klassificering och andra klassificeringsdata för generna i den sökvägen (data visas inte)., (B) den Kegg biokemiska vägen som visas efter valet av pathway-namnet ”apoptosis” i (A) visar fyra differentiellt uttryckta gener inom apoptosvägen genom att markera dem i ljusgrön och röd. Det faktum att KEGG pathway belyser endast fyra gener medan KeggChart kartlägger fem Affymetrix sond sätter till apoptosis pathway beror på det faktum att två sondsatser rikta samma” TNF-alfa ” gen.,
DomainCharts
DomainCharts är operativt besläktade med både KeggCharts och GoCharts, förutom att resultaten visuellt skildrar fördelningen av gener bland PFAM-proteindomäner (figur 6a). DomainCharts histogram identifierar 16 gener med kinasdomäner (pkinas), vilket troligen återspeglar effekterna av HIV-1 gp120 på signaltransduktionsmaskineriet. Diagrammet identifierar också sex gener med interleukin-8 domäner (IL-8), en domän som representerar ett mycket konserverat motiv bland stressrespons cytokiner., Om du väljer domännamnet ” IL8 ” öppnas sidan för den skyddade Domändatabasen (CDD) som motsvarar den PFAM-domänen (figur 6b). Denna sida innehåller detaljerad sekvens, struktur och funktionell information om IL-8-domänen och proteinerna som innehåller den.
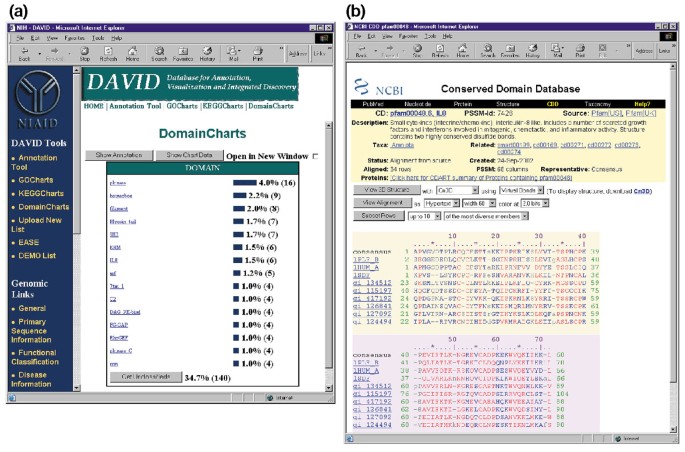
Ouput av DomainCharts. (a) Visualiseringsdiagram som visar fördelningen av 402 gener bland proteindomäner. Parametrarna sattes till ett minimum träfftröskel på fyra och produktionen sorterades efter träffantal., I likhet med produktionen av GoCharts och KeggCharts representerar blåstänger antalet gener som innehåller den specifika domänen. Om du väljer en blå stapel öppnas en HTML-tabell som visar LocusLink, gennamn, aktuell klassificering och andra klassificeringsdata för generna i den sökvägen (data visas inte)., (B) att välja domännamnet ”IL8” i (A), som innehåller sex differentiellt uttryckta gener, ger användaren till en ny sida som innehåller produktionen från NCBI: s konserverade Domändatabas (CDD), som ger detaljerad information om IL-8-domänen, inklusive strukturell information, flera sekvensjusteringar och beskrivande information om domänen och de proteiner som besitter den.